Welcome to nvitop’s documentation!





An interactive NVIDIA-GPU process viewer and beyond, the one-stop solution for GPU process management.
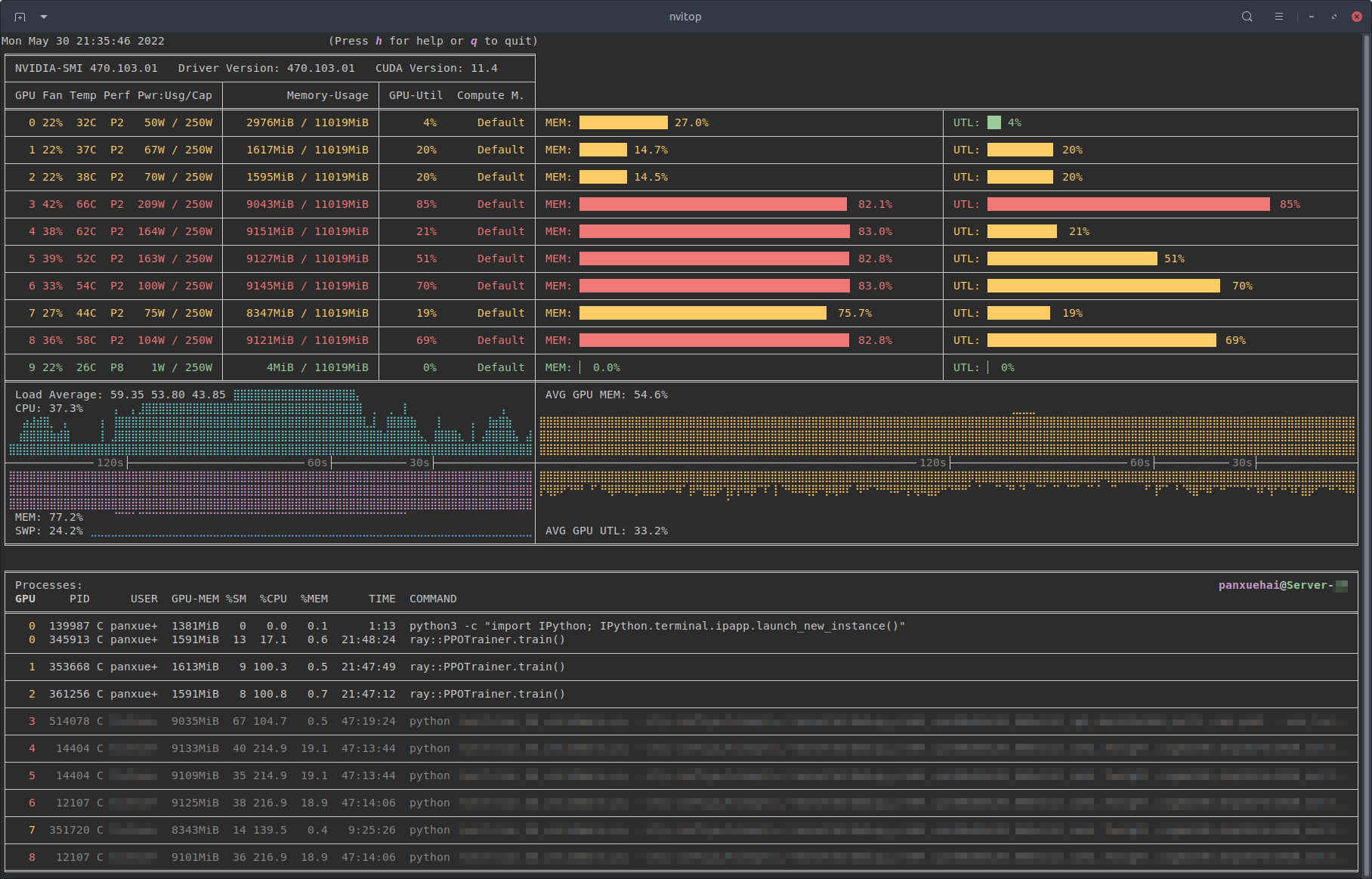
The CLI from nvitop.
Installation
It is highly recommended to install nvitop in an isolated virtual environment. Simple installation and run via uvx (a.k.a. uv tool run) or pipx:
uvx nvitop
# or
pipx run nvitop
Install from PyPI (
pip3 install --upgrade nvitop
Note
Python 3.8+ is required, and Python versions lower than 3.8 are not supported.
Install from conda-forge (
conda install -c conda-forge nvitop
Install the latest version from GitHub (
pip3 install --upgrade pip setuptools
pip3 install git+https://github.com/XuehaiPan/nvitop.git
Or, clone this repo and install manually:
git clone --depth=1 https://github.com/XuehaiPan/nvitop.git && cd nvitop
pip3 install .
If this repo is useful to you, please star ⭐️ it to let more people know 🤗.
Quick Start
A minimal script to monitor the GPU devices based on APIs from nvitop:
from nvitop import Device
devices = Device.all() # or Device.cuda.all()
for device in devices:
processes = device.processes() # type: Dict[int, GpuProcess]
sorted_pids = sorted(processes)
print(device)
print(f' - Fan speed: {device.fan_speed()}%')
print(f' - Temperature: {device.temperature()}C')
print(f' - GPU utilization: {device.gpu_utilization()}%')
print(f' - Total memory: {device.memory_total_human()}')
print(f' - Used memory: {device.memory_used_human()}')
print(f' - Free memory: {device.memory_free_human()}')
print(f' - Processes ({len(processes)}): {sorted_pids}')
for pid in sorted_pids:
print(f' - {processes[pid]}')
print('-' * 120)
Another more advanced approach with coloring:
import time
from nvitop import Device, GpuProcess, NA, colored
print(colored(time.strftime('%a %b %d %H:%M:%S %Y'), color='red', attrs=('bold',)))
devices = Device.cuda.all() # or `Device.all()` to use NVML ordinal instead
separator = False
for device in devices:
processes = device.processes() # type: Dict[int, GpuProcess]
print(colored(str(device), color='green', attrs=('bold',)))
print(colored(' - Fan speed: ', color='blue', attrs=('bold',)) + f'{device.fan_speed()}%')
print(colored(' - Temperature: ', color='blue', attrs=('bold',)) + f'{device.temperature()}C')
print(colored(' - GPU utilization: ', color='blue', attrs=('bold',)) + f'{device.gpu_utilization()}%')
print(colored(' - Total memory: ', color='blue', attrs=('bold',)) + f'{device.memory_total_human()}')
print(colored(' - Used memory: ', color='blue', attrs=('bold',)) + f'{device.memory_used_human()}')
print(colored(' - Free memory: ', color='blue', attrs=('bold',)) + f'{device.memory_free_human()}')
if len(processes) > 0:
processes = GpuProcess.take_snapshots(processes.values(), failsafe=True)
processes.sort(key=lambda process: (process.username, process.pid))
print(colored(f' - Processes ({len(processes)}):', color='blue', attrs=('bold',)))
fmt = ' {pid:<5} {username:<8} {cpu:>5} {host_memory:>8} {time:>8} {gpu_memory:>8} {sm:>3} {command:<}'.format
print(colored(fmt(pid='PID', username='USERNAME',
cpu='CPU%', host_memory='HOST-MEM', time='TIME',
gpu_memory='GPU-MEM', sm='SM%',
command='COMMAND'),
attrs=('bold',)))
for snapshot in processes:
print(fmt(pid=snapshot.pid,
username=snapshot.username[:7] + ('+' if len(snapshot.username) > 8 else snapshot.username[7:8]),
cpu=snapshot.cpu_percent, host_memory=snapshot.host_memory_human,
time=snapshot.running_time_human,
gpu_memory=(snapshot.gpu_memory_human if snapshot.gpu_memory_human is not NA else 'WDDM:N/A'),
sm=snapshot.gpu_sm_utilization,
command=snapshot.command))
else:
print(colored(' - No Running Processes', attrs=('bold',)))
if separator:
print('-' * 120)
separator = True

An example monitoring script built with APIs from nvitop.
Please refer to section More than a Monitor in README for more examples.
API Reference
- nvitop.device module
DeviceDevice.UUID_PATTERNDevice.GPU_PROCESS_CLASSDevice.cudaDevice.is_available()Device.driver_version()Device.cuda_driver_version()Device.max_cuda_version()Device.cuda_runtime_version()Device.cudart_version()Device.count()Device.all()Device.from_indices()Device.from_cuda_visible_devices()Device.from_cuda_indices()Device.parse_cuda_visible_devices()Device.normalize_cuda_visible_devices()Device.__new__()Device.__init__()Device.__repr__()Device.__eq__()Device.__hash__()Device.__getattr__()Device.__reduce__()Device.indexDevice.nvml_indexDevice.physical_indexDevice.handleDevice.cuda_indexDevice.name()Device.uuid()Device.bus_id()Device.serial()Device.memory_info()Device.memory_total()Device.memory_used()Device.memory_free()Device.memory_total_human()Device.memory_used_human()Device.memory_free_human()Device.memory_percent()Device.memory_usage()Device.bar1_memory_info()Device.bar1_memory_total()Device.bar1_memory_used()Device.bar1_memory_free()Device.bar1_memory_total_human()Device.bar1_memory_used_human()Device.bar1_memory_free_human()Device.bar1_memory_percent()Device.bar1_memory_usage()Device.utilization_rates()Device.gpu_utilization()Device.gpu_percent()Device.memory_utilization()Device.encoder_utilization()Device.decoder_utilization()Device.clock_infos()Device.clocks()Device.max_clock_infos()Device.max_clocks()Device.clock_speed_infos()Device.graphics_clock()Device.sm_clock()Device.memory_clock()Device.video_clock()Device.max_graphics_clock()Device.max_sm_clock()Device.max_memory_clock()Device.max_video_clock()Device.fan_speed()Device.temperature()Device.power_usage()Device.power_draw()Device.power_limit()Device.power_status()Device.pcie_throughput()Device.pcie_tx_throughput()Device.pcie_rx_throughput()Device.pcie_tx_throughput_human()Device.pcie_rx_throughput_human()Device.nvlink_link_count()Device.nvlink_throughput()Device.nvlink_total_throughput()Device.nvlink_mean_throughput()Device.nvlink_tx_throughput()Device.nvlink_mean_tx_throughput()Device.nvlink_total_tx_throughput()Device.nvlink_rx_throughput()Device.nvlink_mean_rx_throughput()Device.nvlink_total_rx_throughput()Device.nvlink_tx_throughput_human()Device.nvlink_mean_tx_throughput_human()Device.nvlink_total_tx_throughput_human()Device.nvlink_rx_throughput_human()Device.nvlink_mean_rx_throughput_human()Device.nvlink_total_rx_throughput_human()Device.display_active()Device.display_mode()Device.current_driver_model()Device.driver_model()Device.persistence_mode()Device.performance_state()Device.total_volatile_uncorrected_ecc_errors()Device.compute_mode()Device.cuda_compute_capability()Device.is_mig_device()Device.mig_mode()Device.is_mig_mode_enabled()Device.max_mig_device_count()Device.mig_devices()Device.is_leaf_device()Device.to_leaf_devices()Device.processes()Device.as_snapshot()Device.SNAPSHOT_KEYSDevice.oneshot()
PhysicalDeviceMigDeviceCudaDeviceCudaMigDeviceparse_cuda_visible_devices()normalize_cuda_visible_devices()
- nvitop.process module
HostProcessHostProcess.INSTANCE_LOCKHostProcess.INSTANCESHostProcess.__new__()HostProcess.__init__()HostProcess.__repr__()HostProcess.__reduce__()HostProcess.username()HostProcess.cmdline()HostProcess.command()HostProcess.running_time()HostProcess.running_time_human()HostProcess.running_time_in_seconds()HostProcess.elapsed_time()HostProcess.elapsed_time_human()HostProcess.elapsed_time_in_seconds()HostProcess.rss_memory()HostProcess.parent()HostProcess.children()HostProcess.oneshot()HostProcess.as_snapshot()HostProcess.as_dict()HostProcess.connections()HostProcess.cpu_affinity()HostProcess.cpu_num()HostProcess.cpu_percent()HostProcess.cpu_times()HostProcess.create_time()HostProcess.cwd()HostProcess.environ()HostProcess.exe()HostProcess.gids()HostProcess.io_counters()HostProcess.ionice()HostProcess.is_running()HostProcess.kill()HostProcess.memory_full_info()HostProcess.memory_info()HostProcess.memory_maps()HostProcess.memory_percent()HostProcess.name()HostProcess.net_connections()HostProcess.nice()HostProcess.num_ctx_switches()HostProcess.num_fds()HostProcess.num_threads()HostProcess.open_files()HostProcess.parents()HostProcess.pidHostProcess.ppid()HostProcess.resume()HostProcess.rlimit()HostProcess.send_signal()HostProcess.status()HostProcess.suspend()HostProcess.terminal()HostProcess.terminate()HostProcess.threads()HostProcess.uids()HostProcess.wait()
GpuProcessGpuProcess.INSTANCE_LOCKGpuProcess.INSTANCESGpuProcess.__new__()GpuProcess.__init__()GpuProcess.__repr__()GpuProcess.__eq__()GpuProcess.__hash__()GpuProcess.__getattr__()GpuProcess.pidGpuProcess.hostGpuProcess.deviceGpuProcess.gpu_instance_id()GpuProcess.compute_instance_id()GpuProcess.gpu_memory()GpuProcess.gpu_memory_human()GpuProcess.gpu_memory_percent()GpuProcess.gpu_sm_utilization()GpuProcess.gpu_memory_utilization()GpuProcess.gpu_encoder_utilization()GpuProcess.gpu_decoder_utilization()GpuProcess.set_gpu_memory()GpuProcess.set_gpu_utilization()GpuProcess.update_gpu_status()GpuProcess.typeGpuProcess.is_running()GpuProcess.status()GpuProcess.create_time()GpuProcess.running_time()GpuProcess.running_time_human()GpuProcess.running_time_in_seconds()GpuProcess.elapsed_time()GpuProcess.elapsed_time_human()GpuProcess.elapsed_time_in_seconds()GpuProcess.username()GpuProcess.name()GpuProcess.cpu_percent()GpuProcess.memory_percent()GpuProcess.host_memory_percent()GpuProcess.host_memory()GpuProcess.host_memory_human()GpuProcess.rss_memory()GpuProcess.cmdline()GpuProcess.command()GpuProcess.host_snapshot()GpuProcess.as_snapshot()GpuProcess.take_snapshots()GpuProcess.failsafe()
command_join()
- nvitop.host module
WINDOWS_SUBSYSTEM_FOR_LINUXPsutilErrorgetuser()hostname()load_average()memory_percent()ppid_map()reverse_ppid_map()swap_percent()uptime()NoSuchProcessZombieProcessAccessDeniedTimeoutExpiredProcessProcess.pidProcess.oneshot()Process.as_dict()Process.parent()Process.parents()Process.is_running()Process.ppid()Process.name()Process.exe()Process.cmdline()Process.status()Process.username()Process.create_time()Process.cwd()Process.nice()Process.uids()Process.gids()Process.terminal()Process.num_fds()Process.io_counters()Process.ionice()Process.rlimit()Process.cpu_affinity()Process.cpu_num()Process.environ()Process.num_ctx_switches()Process.num_threads()Process.threads()Process.children()Process.cpu_percent()Process.cpu_times()Process.memory_info()Process.memory_full_info()Process.memory_percent()Process.memory_maps()Process.open_files()Process.net_connections()Process.connections()Process.send_signal()Process.suspend()Process.resume()Process.terminate()Process.kill()Process.wait()
Popenpid_exists()pids()process_iter()wait_procs()virtual_memory()swap_memory()cpu_times()cpu_percent()cpu_times_percent()cpu_count()cpu_stats()net_io_counters()net_connections()net_if_addrs()net_if_stats()disk_io_counters()disk_partitions()disk_usage()users()boot_time()cpu_freq()getloadavg()sensors_temperatures()sensors_fans()sensors_battery()heap_info()heap_trim()
- nvitop.collector module
take_snapshots()collect_in_background()ResourceMetricCollectorResourceMetricCollector.DEVICE_METRICSResourceMetricCollector.PROCESS_METRICSResourceMetricCollector.__init__()ResourceMetricCollector.activate()ResourceMetricCollector.start()ResourceMetricCollector.deactivate()ResourceMetricCollector.stop()ResourceMetricCollector.context()ResourceMetricCollector.__call__()ResourceMetricCollector.clear()ResourceMetricCollector.reset()ResourceMetricCollector.collect()ResourceMetricCollector.daemonize()ResourceMetricCollector.__del__()ResourceMetricCollector.take_snapshots()
- nvitop.libnvml module
- Constants
NVML_ERROR_UNINITIALIZEDNVML_ERROR_INVALID_ARGUMENTNVML_ERROR_NOT_SUPPORTEDNVML_ERROR_NO_PERMISSIONNVML_ERROR_ALREADY_INITIALIZEDNVML_ERROR_NOT_FOUNDNVML_ERROR_INSUFFICIENT_SIZENVML_ERROR_INSUFFICIENT_POWERNVML_ERROR_DRIVER_NOT_LOADEDNVML_ERROR_TIMEOUTNVML_ERROR_IRQ_ISSUENVML_ERROR_LIBRARY_NOT_FOUNDNVML_ERROR_FUNCTION_NOT_FOUNDNVML_ERROR_CORRUPTED_INFOROMNVML_ERROR_GPU_IS_LOSTNVML_ERROR_RESET_REQUIREDNVML_ERROR_OPERATING_SYSTEMNVML_ERROR_LIB_RM_VERSION_MISMATCHNVML_ERROR_IN_USENVML_ERROR_MEMORYNVML_ERROR_NO_DATANVML_ERROR_VGPU_ECC_NOT_SUPPORTEDNVML_ERROR_INSUFFICIENT_RESOURCESNVML_ERROR_FREQ_NOT_SUPPORTEDNVML_ERROR_ARGUMENT_VERSION_MISMATCHNVML_ERROR_DEPRECATEDNVML_ERROR_NOT_READYNVML_ERROR_GPU_NOT_FOUNDNVML_ERROR_INVALID_STATENVML_ERROR_RESET_TYPE_NOT_SUPPORTEDNVML_ERROR_UNKNOWNNVML_FEATURE_DISABLEDNVML_FEATURE_ENABLEDNVML_BRAND_UNKNOWNNVML_BRAND_QUADRONVML_BRAND_TESLANVML_BRAND_NVSNVML_BRAND_GRIDNVML_BRAND_GEFORCENVML_BRAND_TITANNVML_BRAND_NVIDIA_VAPPSNVML_BRAND_NVIDIA_VPCNVML_BRAND_NVIDIA_VCSNVML_BRAND_NVIDIA_VWSNVML_BRAND_NVIDIA_CLOUD_GAMINGNVML_BRAND_NVIDIA_VGAMINGNVML_BRAND_QUADRO_RTXNVML_BRAND_NVIDIA_RTXNVML_BRAND_NVIDIANVML_BRAND_GEFORCE_RTXNVML_BRAND_TITAN_RTXNVML_BRAND_COUNTNVML_TEMPERATURE_THRESHOLD_SHUTDOWNNVML_TEMPERATURE_THRESHOLD_SLOWDOWNNVML_TEMPERATURE_THRESHOLD_MEM_MAXNVML_TEMPERATURE_THRESHOLD_GPU_MAXNVML_TEMPERATURE_THRESHOLD_ACOUSTIC_MINNVML_TEMPERATURE_THRESHOLD_ACOUSTIC_CURRNVML_TEMPERATURE_THRESHOLD_ACOUSTIC_MAXNVML_TEMPERATURE_THRESHOLD_GPS_CURRNVML_TEMPERATURE_THRESHOLD_COUNTNVML_TEMPERATURE_GPUNVML_TEMPERATURE_COUNTNVML_COMPUTEMODE_DEFAULTNVML_COMPUTEMODE_EXCLUSIVE_THREADNVML_COMPUTEMODE_PROHIBITEDNVML_COMPUTEMODE_EXCLUSIVE_PROCESSNVML_COMPUTEMODE_COUNTNVML_MEMORY_LOCATION_L1_CACHENVML_MEMORY_LOCATION_L2_CACHENVML_MEMORY_LOCATION_DEVICE_MEMORYNVML_MEMORY_LOCATION_DRAMNVML_MEMORY_LOCATION_REGISTER_FILENVML_MEMORY_LOCATION_TEXTURE_MEMORYNVML_MEMORY_LOCATION_TEXTURE_SHMNVML_MEMORY_LOCATION_CBUNVML_MEMORY_LOCATION_SRAMNVML_MEMORY_LOCATION_COUNTNVML_NVLINK_MAX_LINKSNVML_NVLINK_MAX_LANESNVML_NVLINK_ERROR_DL_REPLAYNVML_NVLINK_ERROR_DL_RECOVERYNVML_NVLINK_ERROR_DL_CRC_FLITNVML_NVLINK_ERROR_DL_CRC_DATANVML_NVLINK_ERROR_DL_ECC_DATANVML_NVLINK_ERROR_COUNTNVML_NVLINK_ERROR_DL_ECC_LANE0NVML_NVLINK_ERROR_DL_ECC_LANE1NVML_NVLINK_ERROR_DL_ECC_LANE2NVML_NVLINK_ERROR_DL_ECC_LANE3NVML_NVLINK_ERROR_DL_ECC_COUNTNVML_NVLINK_CAP_P2P_SUPPORTEDNVML_NVLINK_CAP_SYSMEM_ACCESSNVML_NVLINK_CAP_P2P_ATOMICSNVML_NVLINK_CAP_SYSMEM_ATOMICSNVML_NVLINK_CAP_SLI_BRIDGENVML_NVLINK_CAP_VALIDNVML_NVLINK_CAP_COUNTNVML_NVLINK_COUNTER_PKTFILTER_NOPNVML_NVLINK_COUNTER_PKTFILTER_READNVML_NVLINK_COUNTER_PKTFILTER_WRITENVML_NVLINK_COUNTER_PKTFILTER_RATOMNVML_NVLINK_COUNTER_PKTFILTER_NRATOMNVML_NVLINK_COUNTER_PKTFILTER_FLUSHNVML_NVLINK_COUNTER_PKTFILTER_RESPDATANVML_NVLINK_COUNTER_PKTFILTER_RESPNODATANVML_NVLINK_COUNTER_PKTFILTER_ALLNVML_NVLINK_COUNTER_UNIT_CYCLESNVML_NVLINK_COUNTER_UNIT_PACKETSNVML_NVLINK_COUNTER_UNIT_BYTESNVML_NVLINK_COUNTER_UNIT_RESERVEDNVML_NVLINK_COUNTER_UNIT_COUNTNVML_NVLINK_DEVICE_TYPE_GPUNVML_NVLINK_DEVICE_TYPE_IBMNPUNVML_NVLINK_DEVICE_TYPE_SWITCHNVML_NVLINK_DEVICE_TYPE_UNKNOWNNVML_SINGLE_BIT_ECCNVML_DOUBLE_BIT_ECCNVML_ECC_ERROR_TYPE_COUNTNVML_VOLATILE_ECCNVML_AGGREGATE_ECCNVML_ECC_COUNTER_TYPE_COUNTNVML_MEMORY_ERROR_TYPE_CORRECTEDNVML_MEMORY_ERROR_TYPE_UNCORRECTEDNVML_MEMORY_ERROR_TYPE_COUNTNVML_CLOCK_GRAPHICSNVML_CLOCK_SMNVML_CLOCK_MEMNVML_CLOCK_VIDEONVML_CLOCK_COUNTNVML_CLOCK_ID_CURRENTNVML_CLOCK_ID_APP_CLOCK_TARGETNVML_CLOCK_ID_APP_CLOCK_DEFAULTNVML_CLOCK_ID_CUSTOMER_BOOST_MAXNVML_CLOCK_ID_COUNTNVML_DRIVER_WDDMNVML_DRIVER_WDMNVML_DRIVER_MCDMNVML_MAX_GPU_PERF_PSTATESNVML_PSTATE_0NVML_PSTATE_1NVML_PSTATE_2NVML_PSTATE_3NVML_PSTATE_4NVML_PSTATE_5NVML_PSTATE_6NVML_PSTATE_7NVML_PSTATE_8NVML_PSTATE_9NVML_PSTATE_10NVML_PSTATE_11NVML_PSTATE_12NVML_PSTATE_13NVML_PSTATE_14NVML_PSTATE_15NVML_PSTATE_UNKNOWNNVML_INFOROM_OEMNVML_INFOROM_ECCNVML_INFOROM_POWERNVML_INFOROM_DENNVML_INFOROM_COUNTNVML_SUCCESSNVML_FAN_NORMALNVML_FAN_FAILEDNVML_FAN_POLICY_TEMPERATURE_CONTINOUS_SWNVML_FAN_POLICY_MANUALNVML_LED_COLOR_GREENNVML_LED_COLOR_AMBERNVML_GOM_ALL_ONNVML_GOM_COMPUTENVML_GOM_LOW_DPNVML_PAGE_RETIREMENT_CAUSE_MULTIPLE_SINGLE_BIT_ECC_ERRORSNVML_PAGE_RETIREMENT_CAUSE_DOUBLE_BIT_ECC_ERRORNVML_PAGE_RETIREMENT_CAUSE_COUNTNVML_RESTRICTED_API_SET_APPLICATION_CLOCKSNVML_RESTRICTED_API_SET_AUTO_BOOSTED_CLOCKSNVML_RESTRICTED_API_COUNTNVML_BRIDGE_CHIP_PLXNVML_BRIDGE_CHIP_BRO4NVML_MAX_PHYSICAL_BRIDGENVML_VALUE_TYPE_DOUBLENVML_VALUE_TYPE_UNSIGNED_INTNVML_VALUE_TYPE_UNSIGNED_LONGNVML_VALUE_TYPE_UNSIGNED_LONG_LONGNVML_VALUE_TYPE_SIGNED_LONG_LONGNVML_VALUE_TYPE_SIGNED_INTNVML_VALUE_TYPE_UNSIGNED_SHORTNVML_VALUE_TYPE_COUNTNVML_NVLINK_VERSION_INVALIDNVML_NVLINK_VERSION_1_0NVML_NVLINK_VERSION_2_0NVML_NVLINK_VERSION_2_2NVML_NVLINK_VERSION_3_0NVML_NVLINK_VERSION_3_1NVML_NVLINK_VERSION_4_0NVML_NVLINK_VERSION_5_0NVML_NVLINK_VERSION_6_0NVML_PERF_POLICY_POWERNVML_PERF_POLICY_THERMALNVML_PERF_POLICY_SYNC_BOOSTNVML_PERF_POLICY_BOARD_LIMITNVML_PERF_POLICY_LOW_UTILIZATIONNVML_PERF_POLICY_RELIABILITYNVML_PERF_POLICY_TOTAL_APP_CLOCKSNVML_PERF_POLICY_TOTAL_BASE_CLOCKSNVML_PERF_POLICY_COUNTNVML_ENCODER_QUERY_H264NVML_ENCODER_QUERY_HEVCNVML_ENCODER_QUERY_AV1NVML_ENCODER_QUERY_UNKNOWNNVML_FBC_SESSION_TYPE_UNKNOWNNVML_FBC_SESSION_TYPE_TOSYSNVML_FBC_SESSION_TYPE_CUDANVML_FBC_SESSION_TYPE_VIDNVML_FBC_SESSION_TYPE_HWENCNVML_DETACH_GPU_KEEPNVML_DETACH_GPU_REMOVENVML_PCIE_LINK_KEEPNVML_PCIE_LINK_SHUT_DOWNNVML_TOTAL_POWER_SAMPLESNVML_GPU_UTILIZATION_SAMPLESNVML_MEMORY_UTILIZATION_SAMPLESNVML_ENC_UTILIZATION_SAMPLESNVML_DEC_UTILIZATION_SAMPLESNVML_PROCESSOR_CLK_SAMPLESNVML_MEMORY_CLK_SAMPLESNVML_MODULE_POWER_SAMPLESNVML_JPG_UTILIZATION_SAMPLESNVML_OFA_UTILIZATION_SAMPLESNVML_SAMPLINGTYPE_COUNTNVML_PCIE_UTIL_TX_BYTESNVML_PCIE_UTIL_RX_BYTESNVML_PCIE_UTIL_COUNTNVML_TOPOLOGY_INTERNALNVML_TOPOLOGY_SINGLENVML_TOPOLOGY_MULTIPLENVML_TOPOLOGY_HOSTBRIDGENVML_TOPOLOGY_NODENVML_TOPOLOGY_CPUNVML_TOPOLOGY_SYSTEMNVML_P2P_CAPS_INDEX_READNVML_P2P_CAPS_INDEX_WRITENVML_P2P_CAPS_INDEX_NVLINKNVML_P2P_CAPS_INDEX_ATOMICSNVML_P2P_CAPS_INDEX_PROPNVML_P2P_CAPS_INDEX_PCINVML_P2P_CAPS_INDEX_UNKNOWNNVML_P2P_STATUS_OKNVML_P2P_STATUS_CHIPSET_NOT_SUPPOREDNVML_P2P_STATUS_CHIPSET_NOT_SUPPORTEDNVML_P2P_STATUS_GPU_NOT_SUPPORTEDNVML_P2P_STATUS_IOH_TOPOLOGY_NOT_SUPPORTEDNVML_P2P_STATUS_DISABLED_BY_REGKEYNVML_P2P_STATUS_NOT_SUPPORTEDNVML_P2P_STATUS_UNKNOWNNVML_DEVICE_ARCH_KEPLERNVML_DEVICE_ARCH_MAXWELLNVML_DEVICE_ARCH_PASCALNVML_DEVICE_ARCH_VOLTANVML_DEVICE_ARCH_TURINGNVML_DEVICE_ARCH_AMPERENVML_DEVICE_ARCH_ADANVML_DEVICE_ARCH_HOPPERNVML_DEVICE_ARCH_BLACKWELLNVML_DEVICE_ARCH_RUBINNVML_DEVICE_ARCH_UNKNOWNNVML_BUS_TYPE_UNKNOWNNVML_BUS_TYPE_PCINVML_BUS_TYPE_PCIENVML_BUS_TYPE_FPCINVML_BUS_TYPE_AGPNVML_POWER_SOURCE_ACNVML_POWER_SOURCE_BATTERYNVML_POWER_SOURCE_UNDERSIZEDNVML_ADAPTIVE_CLOCKING_INFO_STATUS_DISABLEDNVML_ADAPTIVE_CLOCKING_INFO_STATUS_ENABLEDNVML_CLOCK_LIMIT_ID_RANGE_STARTNVML_CLOCK_LIMIT_ID_TDPNVML_CLOCK_LIMIT_ID_UNLIMITEDNVML_PCIE_LINK_MAX_SPEED_INVALIDNVML_PCIE_LINK_MAX_SPEED_2500MBPSNVML_PCIE_LINK_MAX_SPEED_5000MBPSNVML_PCIE_LINK_MAX_SPEED_8000MBPSNVML_PCIE_LINK_MAX_SPEED_16000MBPSNVML_PCIE_LINK_MAX_SPEED_32000MBPSNVML_PCIE_LINK_MAX_SPEED_64000MBPSNVML_PCIE_ATOMICS_CAP_FETCHADD32NVML_PCIE_ATOMICS_CAP_FETCHADD64NVML_PCIE_ATOMICS_CAP_SWAP32NVML_PCIE_ATOMICS_CAP_SWAP64NVML_PCIE_ATOMICS_CAP_CAS32NVML_PCIE_ATOMICS_CAP_CAS64NVML_PCIE_ATOMICS_CAP_CAS128NVML_PCIE_ATOMICS_OPS_MAXNVML_AFFINITY_SCOPE_NODENVML_AFFINITY_SCOPE_SOCKETNVML_GPU_RECOVERY_ACTION_NONENVML_GPU_RECOVERY_ACTION_GPU_RESETNVML_GPU_RECOVERY_ACTION_NODE_REBOOTNVML_GPU_RECOVERY_ACTION_DRAIN_P2PNVML_GPU_RECOVERY_ACTION_DRAIN_AND_RESETNVML_GPU_RECOVERY_ACTION_RECOVER_IMEX_DOMAINNVML_INIT_FLAG_NO_GPUSNVML_INIT_FLAG_NO_ATTACHNVML_INIT_FLAG_FORCE_INITNVML_MAX_GPC_COUNTNVML_DEVICE_INFOROM_VERSION_BUFFER_SIZENVML_DEVICE_UUID_BUFFER_SIZENVML_DEVICE_UUID_V2_BUFFER_SIZENVML_SYSTEM_DRIVER_VERSION_BUFFER_SIZENVML_SYSTEM_NVML_VERSION_BUFFER_SIZENVML_DEVICE_NAME_BUFFER_SIZENVML_DEVICE_NAME_V2_BUFFER_SIZENVML_DEVICE_SERIAL_BUFFER_SIZENVML_DEVICE_PART_NUMBER_BUFFER_SIZENVML_DEVICE_GPU_PART_NUMBER_BUFFER_SIZENVML_DEVICE_VBIOS_VERSION_BUFFER_SIZENVML_DEVICE_PCI_BUS_ID_BUFFER_SIZENVML_DEVICE_PCI_BUS_ID_BUFFER_V2_SIZENVML_GRID_LICENSE_BUFFER_SIZENVML_VGPU_NAME_BUFFER_SIZENVML_GRID_LICENSE_FEATURE_MAX_COUNTNVML_VGPU_METADATA_OPAQUE_DATA_SIZENVML_VGPU_PGPU_METADATA_OPAQUE_DATA_SIZENVML_DEVICE_GPU_FRU_PART_NUMBER_BUFFER_SIZENVML_PERF_MODES_BUFFER_SIZENVML_DEVICE_PCI_BUS_ID_LEGACY_FMTNVML_DEVICE_PCI_BUS_ID_FMTNVML_VALUE_NOT_AVAILABLE_ulonglongNVML_VALUE_NOT_AVAILABLE_uintNVML_FI_DEV_ECC_CURRENTNVML_FI_DEV_ECC_PENDINGNVML_FI_DEV_ECC_SBE_VOL_TOTALNVML_FI_DEV_ECC_DBE_VOL_TOTALNVML_FI_DEV_ECC_SBE_AGG_TOTALNVML_FI_DEV_ECC_DBE_AGG_TOTALNVML_FI_DEV_ECC_SBE_VOL_L1NVML_FI_DEV_ECC_DBE_VOL_L1NVML_FI_DEV_ECC_SBE_VOL_L2NVML_FI_DEV_ECC_DBE_VOL_L2NVML_FI_DEV_ECC_SBE_VOL_DEVNVML_FI_DEV_ECC_DBE_VOL_DEVNVML_FI_DEV_ECC_SBE_VOL_REGNVML_FI_DEV_ECC_DBE_VOL_REGNVML_FI_DEV_ECC_SBE_VOL_TEXNVML_FI_DEV_ECC_DBE_VOL_TEXNVML_FI_DEV_ECC_DBE_VOL_CBUNVML_FI_DEV_ECC_SBE_AGG_L1NVML_FI_DEV_ECC_DBE_AGG_L1NVML_FI_DEV_ECC_SBE_AGG_L2NVML_FI_DEV_ECC_DBE_AGG_L2NVML_FI_DEV_ECC_SBE_AGG_DEVNVML_FI_DEV_ECC_DBE_AGG_DEVNVML_FI_DEV_ECC_SBE_AGG_REGNVML_FI_DEV_ECC_DBE_AGG_REGNVML_FI_DEV_ECC_SBE_AGG_TEXNVML_FI_DEV_ECC_DBE_AGG_TEXNVML_FI_DEV_ECC_DBE_AGG_CBUNVML_FI_DEV_RETIRED_SBENVML_FI_DEV_RETIRED_DBENVML_FI_DEV_RETIRED_PENDINGNVML_FI_DEV_NVLINK_CRC_FLIT_ERROR_COUNT_L0NVML_FI_DEV_NVLINK_CRC_FLIT_ERROR_COUNT_L1NVML_FI_DEV_NVLINK_CRC_FLIT_ERROR_COUNT_L2NVML_FI_DEV_NVLINK_CRC_FLIT_ERROR_COUNT_L3NVML_FI_DEV_NVLINK_CRC_FLIT_ERROR_COUNT_L4NVML_FI_DEV_NVLINK_CRC_FLIT_ERROR_COUNT_L5NVML_FI_DEV_NVLINK_CRC_FLIT_ERROR_COUNT_TOTALNVML_FI_DEV_NVLINK_CRC_DATA_ERROR_COUNT_L0NVML_FI_DEV_NVLINK_CRC_DATA_ERROR_COUNT_L1NVML_FI_DEV_NVLINK_CRC_DATA_ERROR_COUNT_L2NVML_FI_DEV_NVLINK_CRC_DATA_ERROR_COUNT_L3NVML_FI_DEV_NVLINK_CRC_DATA_ERROR_COUNT_L4NVML_FI_DEV_NVLINK_CRC_DATA_ERROR_COUNT_L5NVML_FI_DEV_NVLINK_CRC_DATA_ERROR_COUNT_TOTALNVML_FI_DEV_NVLINK_REPLAY_ERROR_COUNT_L0NVML_FI_DEV_NVLINK_REPLAY_ERROR_COUNT_L1NVML_FI_DEV_NVLINK_REPLAY_ERROR_COUNT_L2NVML_FI_DEV_NVLINK_REPLAY_ERROR_COUNT_L3NVML_FI_DEV_NVLINK_REPLAY_ERROR_COUNT_L4NVML_FI_DEV_NVLINK_REPLAY_ERROR_COUNT_L5NVML_FI_DEV_NVLINK_REPLAY_ERROR_COUNT_TOTALNVML_FI_DEV_NVLINK_RECOVERY_ERROR_COUNT_L0NVML_FI_DEV_NVLINK_RECOVERY_ERROR_COUNT_L1NVML_FI_DEV_NVLINK_RECOVERY_ERROR_COUNT_L2NVML_FI_DEV_NVLINK_RECOVERY_ERROR_COUNT_L3NVML_FI_DEV_NVLINK_RECOVERY_ERROR_COUNT_L4NVML_FI_DEV_NVLINK_RECOVERY_ERROR_COUNT_L5NVML_FI_DEV_NVLINK_RECOVERY_ERROR_COUNT_TOTALNVML_FI_DEV_NVLINK_BANDWIDTH_C0_L0NVML_FI_DEV_NVLINK_BANDWIDTH_C0_L1NVML_FI_DEV_NVLINK_BANDWIDTH_C0_L2NVML_FI_DEV_NVLINK_BANDWIDTH_C0_L3NVML_FI_DEV_NVLINK_BANDWIDTH_C0_L4NVML_FI_DEV_NVLINK_BANDWIDTH_C0_L5NVML_FI_DEV_NVLINK_BANDWIDTH_C0_TOTALNVML_FI_DEV_NVLINK_BANDWIDTH_C1_L0NVML_FI_DEV_NVLINK_BANDWIDTH_C1_L1NVML_FI_DEV_NVLINK_BANDWIDTH_C1_L2NVML_FI_DEV_NVLINK_BANDWIDTH_C1_L3NVML_FI_DEV_NVLINK_BANDWIDTH_C1_L4NVML_FI_DEV_NVLINK_BANDWIDTH_C1_L5NVML_FI_DEV_NVLINK_BANDWIDTH_C1_TOTALNVML_FI_DEV_PERF_POLICY_POWERNVML_FI_DEV_PERF_POLICY_THERMALNVML_FI_DEV_PERF_POLICY_SYNC_BOOSTNVML_FI_DEV_PERF_POLICY_BOARD_LIMITNVML_FI_DEV_PERF_POLICY_LOW_UTILIZATIONNVML_FI_DEV_PERF_POLICY_RELIABILITYNVML_FI_DEV_PERF_POLICY_TOTAL_APP_CLOCKSNVML_FI_DEV_PERF_POLICY_TOTAL_BASE_CLOCKSNVML_FI_DEV_MEMORY_TEMPNVML_FI_DEV_TOTAL_ENERGY_CONSUMPTIONNVML_FI_DEV_NVLINK_SPEED_MBPS_L0NVML_FI_DEV_NVLINK_SPEED_MBPS_L1NVML_FI_DEV_NVLINK_SPEED_MBPS_L2NVML_FI_DEV_NVLINK_SPEED_MBPS_L3NVML_FI_DEV_NVLINK_SPEED_MBPS_L4NVML_FI_DEV_NVLINK_SPEED_MBPS_L5NVML_FI_DEV_NVLINK_SPEED_MBPS_COMMONNVML_FI_DEV_NVLINK_LINK_COUNTNVML_FI_DEV_RETIRED_PENDING_SBENVML_FI_DEV_RETIRED_PENDING_DBENVML_FI_DEV_PCIE_REPLAY_COUNTERNVML_FI_DEV_PCIE_REPLAY_ROLLOVER_COUNTERNVML_FI_DEV_NVLINK_CRC_FLIT_ERROR_COUNT_L6NVML_FI_DEV_NVLINK_CRC_FLIT_ERROR_COUNT_L7NVML_FI_DEV_NVLINK_CRC_FLIT_ERROR_COUNT_L8NVML_FI_DEV_NVLINK_CRC_FLIT_ERROR_COUNT_L9NVML_FI_DEV_NVLINK_CRC_FLIT_ERROR_COUNT_L10NVML_FI_DEV_NVLINK_CRC_FLIT_ERROR_COUNT_L11NVML_FI_DEV_NVLINK_CRC_DATA_ERROR_COUNT_L6NVML_FI_DEV_NVLINK_CRC_DATA_ERROR_COUNT_L7NVML_FI_DEV_NVLINK_CRC_DATA_ERROR_COUNT_L8NVML_FI_DEV_NVLINK_CRC_DATA_ERROR_COUNT_L9NVML_FI_DEV_NVLINK_CRC_DATA_ERROR_COUNT_L10NVML_FI_DEV_NVLINK_CRC_DATA_ERROR_COUNT_L11NVML_FI_DEV_NVLINK_REPLAY_ERROR_COUNT_L6NVML_FI_DEV_NVLINK_REPLAY_ERROR_COUNT_L7NVML_FI_DEV_NVLINK_REPLAY_ERROR_COUNT_L8NVML_FI_DEV_NVLINK_REPLAY_ERROR_COUNT_L9NVML_FI_DEV_NVLINK_REPLAY_ERROR_COUNT_L10NVML_FI_DEV_NVLINK_REPLAY_ERROR_COUNT_L11NVML_FI_DEV_NVLINK_RECOVERY_ERROR_COUNT_L6NVML_FI_DEV_NVLINK_RECOVERY_ERROR_COUNT_L7NVML_FI_DEV_NVLINK_RECOVERY_ERROR_COUNT_L8NVML_FI_DEV_NVLINK_RECOVERY_ERROR_COUNT_L9NVML_FI_DEV_NVLINK_RECOVERY_ERROR_COUNT_L10NVML_FI_DEV_NVLINK_RECOVERY_ERROR_COUNT_L11NVML_FI_DEV_NVLINK_BANDWIDTH_C0_L6NVML_FI_DEV_NVLINK_BANDWIDTH_C0_L7NVML_FI_DEV_NVLINK_BANDWIDTH_C0_L8NVML_FI_DEV_NVLINK_BANDWIDTH_C0_L9NVML_FI_DEV_NVLINK_BANDWIDTH_C0_L10NVML_FI_DEV_NVLINK_BANDWIDTH_C0_L11NVML_FI_DEV_NVLINK_BANDWIDTH_C1_L6NVML_FI_DEV_NVLINK_BANDWIDTH_C1_L7NVML_FI_DEV_NVLINK_BANDWIDTH_C1_L8NVML_FI_DEV_NVLINK_BANDWIDTH_C1_L9NVML_FI_DEV_NVLINK_BANDWIDTH_C1_L10NVML_FI_DEV_NVLINK_BANDWIDTH_C1_L11NVML_FI_DEV_NVLINK_SPEED_MBPS_L6NVML_FI_DEV_NVLINK_SPEED_MBPS_L7NVML_FI_DEV_NVLINK_SPEED_MBPS_L8NVML_FI_DEV_NVLINK_SPEED_MBPS_L9NVML_FI_DEV_NVLINK_SPEED_MBPS_L10NVML_FI_DEV_NVLINK_SPEED_MBPS_L11NVML_FI_DEV_NVLINK_THROUGHPUT_DATA_TXNVML_FI_DEV_NVLINK_THROUGHPUT_DATA_RXNVML_FI_DEV_NVLINK_THROUGHPUT_RAW_TXNVML_FI_DEV_NVLINK_THROUGHPUT_RAW_RXNVML_FI_DEV_REMAPPED_CORNVML_FI_DEV_REMAPPED_UNCNVML_FI_DEV_REMAPPED_PENDINGNVML_FI_DEV_REMAPPED_FAILURENVML_FI_DEV_NVLINK_REMOTE_NVLINK_IDNVML_FI_DEV_NVSWITCH_CONNECTED_LINK_COUNTNVML_FI_DEV_NVLINK_ECC_DATA_ERROR_COUNT_L0NVML_FI_DEV_NVLINK_ECC_DATA_ERROR_COUNT_L1NVML_FI_DEV_NVLINK_ECC_DATA_ERROR_COUNT_L2NVML_FI_DEV_NVLINK_ECC_DATA_ERROR_COUNT_L3NVML_FI_DEV_NVLINK_ECC_DATA_ERROR_COUNT_L4NVML_FI_DEV_NVLINK_ECC_DATA_ERROR_COUNT_L5NVML_FI_DEV_NVLINK_ECC_DATA_ERROR_COUNT_L6NVML_FI_DEV_NVLINK_ECC_DATA_ERROR_COUNT_L7NVML_FI_DEV_NVLINK_ECC_DATA_ERROR_COUNT_L8NVML_FI_DEV_NVLINK_ECC_DATA_ERROR_COUNT_L9NVML_FI_DEV_NVLINK_ECC_DATA_ERROR_COUNT_L10NVML_FI_DEV_NVLINK_ECC_DATA_ERROR_COUNT_L11NVML_FI_DEV_NVLINK_ECC_DATA_ERROR_COUNT_TOTALNVML_FI_DEV_NVLINK_ERROR_DL_REPLAYNVML_FI_DEV_NVLINK_ERROR_DL_RECOVERYNVML_FI_DEV_NVLINK_ERROR_DL_CRCNVML_FI_DEV_NVLINK_GET_SPEEDNVML_FI_DEV_NVLINK_GET_STATENVML_FI_DEV_NVLINK_GET_VERSIONNVML_FI_DEV_NVLINK_GET_POWER_STATENVML_FI_DEV_NVLINK_GET_POWER_THRESHOLDNVML_FI_DEV_PCIE_L0_TO_RECOVERY_COUNTERNVML_FI_DEV_C2C_LINK_COUNTNVML_FI_DEV_C2C_LINK_GET_STATUSNVML_FI_DEV_C2C_LINK_GET_MAX_BWNVML_FI_DEV_PCIE_COUNT_CORRECTABLE_ERRORSNVML_FI_DEV_PCIE_COUNT_NAKS_RECEIVEDNVML_FI_DEV_PCIE_COUNT_RECEIVER_ERRORNVML_FI_DEV_PCIE_COUNT_BAD_TLPNVML_FI_DEV_PCIE_COUNT_NAKS_SENTNVML_FI_DEV_PCIE_COUNT_BAD_DLLPNVML_FI_DEV_PCIE_COUNT_NON_FATAL_ERRORNVML_FI_DEV_PCIE_COUNT_FATAL_ERRORNVML_FI_DEV_PCIE_COUNT_UNSUPPORTED_REQNVML_FI_DEV_PCIE_COUNT_LCRC_ERRORNVML_FI_DEV_PCIE_COUNT_LANE_ERRORNVML_FI_DEV_IS_RESETLESS_MIG_SUPPORTEDNVML_FI_DEV_POWER_AVERAGENVML_FI_DEV_POWER_INSTANTNVML_FI_DEV_POWER_MIN_LIMITNVML_FI_DEV_POWER_MAX_LIMITNVML_FI_DEV_POWER_DEFAULT_LIMITNVML_FI_DEV_POWER_CURRENT_LIMITNVML_FI_DEV_ENERGYNVML_FI_DEV_POWER_REQUESTED_LIMITNVML_FI_DEV_TEMPERATURE_SHUTDOWN_TLIMITNVML_FI_DEV_TEMPERATURE_SLOWDOWN_TLIMITNVML_FI_DEV_TEMPERATURE_MEM_MAX_TLIMITNVML_FI_DEV_TEMPERATURE_GPU_MAX_TLIMITNVML_FI_DEV_PCIE_COUNT_TX_BYTESNVML_FI_DEV_PCIE_COUNT_RX_BYTESNVML_FI_DEV_IS_MIG_MODE_INDEPENDENT_MIG_QUERY_CAPABLENVML_FI_DEV_NVLINK_GET_POWER_THRESHOLD_MAXNVML_FI_DEV_NVLINK_COUNT_XMIT_PACKETSNVML_FI_DEV_NVLINK_COUNT_XMIT_BYTESNVML_FI_DEV_NVLINK_COUNT_RCV_PACKETSNVML_FI_DEV_NVLINK_COUNT_RCV_BYTESNVML_FI_DEV_NVLINK_COUNT_VL15_DROPPEDNVML_FI_DEV_NVLINK_COUNT_MALFORMED_PACKET_ERRORSNVML_FI_DEV_NVLINK_COUNT_BUFFER_OVERRUN_ERRORSNVML_FI_DEV_NVLINK_COUNT_RCV_ERRORSNVML_FI_DEV_NVLINK_COUNT_RCV_REMOTE_ERRORSNVML_FI_DEV_NVLINK_COUNT_RCV_GENERAL_ERRORSNVML_FI_DEV_NVLINK_COUNT_LOCAL_LINK_INTEGRITY_ERRORSNVML_FI_DEV_NVLINK_COUNT_XMIT_DISCARDSNVML_FI_DEV_NVLINK_COUNT_LINK_RECOVERY_SUCCESSFUL_EVENTSNVML_FI_DEV_NVLINK_COUNT_LINK_RECOVERY_FAILED_EVENTSNVML_FI_DEV_NVLINK_COUNT_LINK_RECOVERY_EVENTSNVML_FI_DEV_NVLINK_COUNT_RAW_BER_LANE0NVML_FI_DEV_NVLINK_COUNT_RAW_BER_LANE1NVML_FI_DEV_NVLINK_COUNT_RAW_BERNVML_FI_DEV_NVLINK_COUNT_EFFECTIVE_ERRORSNVML_FI_DEV_NVLINK_COUNT_EFFECTIVE_BERNVML_FI_DEV_NVLINK_COUNT_SYMBOL_ERRORSNVML_FI_DEV_NVLINK_COUNT_SYMBOL_BERNVML_FI_DEV_NVLINK_GET_POWER_THRESHOLD_MINNVML_FI_DEV_NVLINK_GET_POWER_THRESHOLD_UNITSNVML_FI_DEV_NVLINK_GET_POWER_THRESHOLD_SUPPORTEDNVML_FI_DEV_RESET_STATUSNVML_FI_DEV_DRAIN_AND_RESET_STATUSNVML_FI_DEV_PCIE_OUTBOUND_ATOMICS_MASKNVML_FI_DEV_PCIE_INBOUND_ATOMICS_MASKNVML_FI_DEV_GET_GPU_RECOVERY_ACTIONNVML_FI_DEV_C2C_LINK_ERROR_INTRNVML_FI_DEV_C2C_LINK_ERROR_REPLAYNVML_FI_DEV_C2C_LINK_ERROR_REPLAY_B2BNVML_FI_DEV_C2C_LINK_POWER_STATENVML_FI_DEV_NVLINK_COUNT_FEC_HISTORY_0NVML_FI_DEV_NVLINK_COUNT_FEC_HISTORY_1NVML_FI_DEV_NVLINK_COUNT_FEC_HISTORY_2NVML_FI_DEV_NVLINK_COUNT_FEC_HISTORY_3NVML_FI_DEV_NVLINK_COUNT_FEC_HISTORY_4NVML_FI_DEV_NVLINK_COUNT_FEC_HISTORY_5NVML_FI_DEV_NVLINK_COUNT_FEC_HISTORY_6NVML_FI_DEV_NVLINK_COUNT_FEC_HISTORY_7NVML_FI_DEV_NVLINK_COUNT_FEC_HISTORY_8NVML_FI_DEV_NVLINK_COUNT_FEC_HISTORY_9NVML_FI_DEV_NVLINK_COUNT_FEC_HISTORY_10NVML_FI_DEV_NVLINK_COUNT_FEC_HISTORY_11NVML_FI_DEV_NVLINK_COUNT_FEC_HISTORY_12NVML_FI_DEV_NVLINK_COUNT_FEC_HISTORY_13NVML_FI_DEV_NVLINK_COUNT_FEC_HISTORY_14NVML_FI_DEV_NVLINK_COUNT_FEC_HISTORY_15NVML_FI_PWR_SMOOTHING_ENABLEDNVML_FI_PWR_SMOOTHING_PRIV_LVLNVML_FI_PWR_SMOOTHING_IMM_RAMP_DOWN_ENABLEDNVML_FI_PWR_SMOOTHING_APPLIED_TMP_CEILNVML_FI_PWR_SMOOTHING_APPLIED_TMP_FLOORNVML_FI_PWR_SMOOTHING_MAX_PERCENT_TMP_FLOOR_SETTINGNVML_FI_PWR_SMOOTHING_MIN_PERCENT_TMP_FLOOR_SETTINGNVML_FI_PWR_SMOOTHING_HW_CIRCUITRY_PERCENT_LIFETIME_REMAININGNVML_FI_PWR_SMOOTHING_MAX_NUM_PRESET_PROFILESNVML_FI_PWR_SMOOTHING_PROFILE_PERCENT_TMP_FLOORNVML_FI_PWR_SMOOTHING_PROFILE_RAMP_UP_RATENVML_FI_PWR_SMOOTHING_PROFILE_RAMP_DOWN_RATENVML_FI_PWR_SMOOTHING_PROFILE_RAMP_DOWN_HYST_VALNVML_FI_PWR_SMOOTHING_ACTIVE_PRESET_PROFILENVML_FI_PWR_SMOOTHING_ADMIN_OVERRIDE_PERCENT_TMP_FLOORNVML_FI_PWR_SMOOTHING_ADMIN_OVERRIDE_RAMP_UP_RATENVML_FI_PWR_SMOOTHING_ADMIN_OVERRIDE_RAMP_DOWN_RATENVML_FI_PWR_SMOOTHING_ADMIN_OVERRIDE_RAMP_DOWN_HYST_VALNVML_FI_DEV_CLOCKS_EVENT_REASON_SW_POWER_CAPNVML_FI_DEV_CLOCKS_EVENT_REASON_SYNC_BOOSTNVML_FI_DEV_CLOCKS_EVENT_REASON_SW_THERM_SLOWDOWNNVML_FI_DEV_CLOCKS_EVENT_REASON_HW_THERM_SLOWDOWNNVML_FI_DEV_CLOCKS_EVENT_REASON_HW_POWER_BRAKE_SLOWDOWNNVML_FI_DEV_POWER_SYNC_BALANCING_FREQNVML_FI_DEV_POWER_SYNC_BALANCING_AFNVML_FI_DEV_EDPP_MULTIPLIERNVML_FI_PWR_SMOOTHING_PRIMARY_POWER_FLOORNVML_FI_PWR_SMOOTHING_SECONDARY_POWER_FLOORNVML_FI_PWR_SMOOTHING_MIN_PRIMARY_FLOOR_ACT_OFFSETNVML_FI_PWR_SMOOTHING_MIN_PRIMARY_FLOOR_ACT_POINTNVML_FI_PWR_SMOOTHING_WINDOW_MULTIPLIERNVML_FI_PWR_SMOOTHING_DELAYED_PWR_SMOOTHING_SUPPORTEDNVML_FI_PWR_SMOOTHING_PROFILE_SECONDARY_POWER_FLOORNVML_FI_PWR_SMOOTHING_PROFILE_PRIMARY_FLOOR_ACT_WIN_MULTNVML_FI_PWR_SMOOTHING_PROFILE_PRIMARY_FLOOR_TAR_WIN_MULTNVML_FI_PWR_SMOOTHING_PROFILE_PRIMARY_FLOOR_ACT_OFFSETNVML_FI_PWR_SMOOTHING_ADMIN_OVERRIDE_SECONDARY_POWER_FLOORNVML_FI_PWR_SMOOTHING_ADMIN_OVERRIDE_PRIMARY_FLOOR_ACT_WIN_MULTNVML_FI_PWR_SMOOTHING_ADMIN_OVERRIDE_PRIMARY_FLOOR_TAR_WIN_MULTNVML_FI_PWR_SMOOTHING_ADMIN_OVERRIDE_PRIMARY_FLOOR_ACT_OFFSETNVML_FI_DEV_NVLINK_COUNT_RAW_ERRORS_LANE0NVML_FI_DEV_NVLINK_COUNT_RAW_ERRORS_LANE1NVML_FI_DEV_NVLINK_COUNT_RAW_BER_LANE0_V2NVML_FI_DEV_NVLINK_COUNT_RAW_BER_LANE1_V2NVML_FI_DEV_NVLINK_COUNT_RAW_BER_V2NVML_FI_DEV_NVLINK_PLR_XMIT_BLOCKSNVML_FI_DEV_NVLINK_PLR_XMIT_RETRY_BLOCKSNVML_FI_DEV_NVLINK_GET_DATA_RATENVML_FI_DEV_MMA_STALL_PERCENTNVML_FI_DEV_MCLK_SWITCH_TYPENVML_FI_DEV_MCLK_MIN_SWITCH_INTERVAL_MILLISECONDSNVML_FI_PWR_SMOOTHING_SOC_POWER_SMOOTHING_ENABLEDNVML_FI_DEV_REMAPPED_ROWS_COR_INACTIVENVML_FI_DEV_REMAPPED_ROWS_UNC_INACTIVENVML_FI_MAXNVML_MCLK_SWITCH_TYPE_NOT_SUPPORTEDNVML_MCLK_SWITCH_TYPE_DEFERREDNVML_MCLK_SWITCH_TYPE_RUNTIMENVML_NVLINK_STATE_INACTIVENVML_NVLINK_STATE_ACTIVENVML_NVLINK_STATE_SLEEPNVML_NVLINK_LOW_POWER_THRESHOLD_UNIT_100USNVML_NVLINK_LOW_POWER_THRESHOLD_UNIT_50USNVML_C2C_POWER_STATE_FULL_POWERNVML_C2C_POWER_STATE_LOW_POWERNVML_GPU_VIRTUALIZATION_MODE_NONENVML_GPU_VIRTUALIZATION_MODE_PASSTHROUGHNVML_GPU_VIRTUALIZATION_MODE_VGPUNVML_GPU_VIRTUALIZATION_MODE_HOST_VGPUNVML_GPU_VIRTUALIZATION_MODE_HOST_VSGANVML_VGPU_VM_ID_DOMAIN_IDNVML_VGPU_VM_ID_UUIDNVML_GRID_LICENSE_FEATURE_CODE_UNKNOWNNVML_GRID_LICENSE_FEATURE_CODE_VGPUNVML_GRID_LICENSE_FEATURE_CODE_NVIDIA_RTXNVML_GRID_LICENSE_FEATURE_CODE_VWORKSTATIONNVML_GRID_LICENSE_FEATURE_CODE_GAMINGNVML_GRID_LICENSE_FEATURE_CODE_COMPUTENVML_GRID_LICENSE_EXPIRY_NOT_AVAILABLENVML_GRID_LICENSE_EXPIRY_INVALIDNVML_GRID_LICENSE_EXPIRY_VALIDNVML_GRID_LICENSE_EXPIRY_NOT_APPLICABLENVML_GRID_LICENSE_EXPIRY_PERMANENTNVML_VGPU_CAP_NVLINK_P2PNVML_VGPU_CAP_GPUDIRECTNVML_VGPU_CAP_MULTI_VGPU_EXCLUSIVENVML_VGPU_CAP_EXCLUSIVE_TYPENVML_VGPU_CAP_EXCLUSIVE_SIZENVML_VGPU_CAP_COUNTNVML_VGPU_DRIVER_CAP_HETEROGENEOUS_MULTI_VGPUNVML_VGPU_DRIVER_CAP_WARM_UPDATENVML_VGPU_DRIVER_CAP_COUNTNVML_DEVICE_VGPU_CAP_FRACTIONAL_MULTI_VGPUNVML_DEVICE_VGPU_CAP_HETEROGENEOUS_TIMESLICE_PROFILESNVML_DEVICE_VGPU_CAP_HETEROGENEOUS_TIMESLICE_SIZESNVML_DEVICE_VGPU_CAP_READ_DEVICE_BUFFER_BWNVML_DEVICE_VGPU_CAP_WRITE_DEVICE_BUFFER_BWNVML_DEVICE_VGPU_CAP_DEVICE_STREAMINGNVML_DEVICE_VGPU_CAP_MINI_QUARTER_GPUNVML_DEVICE_VGPU_CAP_COMPUTE_MEDIA_ENGINE_GPUNVML_DEVICE_VGPU_CAP_WARM_UPDATENVML_DEVICE_VGPU_CAP_HOMOGENEOUS_PLACEMENTSNVML_DEVICE_VGPU_CAP_MIG_TIMESLICING_SUPPORTEDNVML_DEVICE_VGPU_CAP_MIG_TIMESLICING_ENABLEDNVML_DEVICE_VGPU_CAP_COUNTNVML_VGPU_INSTANCE_GUEST_INFO_STATE_UNINITIALIZEDNVML_VGPU_INSTANCE_GUEST_INFO_STATE_INITIALIZEDNVML_VGPU_VM_COMPATIBILITY_NONENVML_VGPU_VM_COMPATIBILITY_COLDNVML_VGPU_VM_COMPATIBILITY_HIBERNATENVML_VGPU_VM_COMPATIBILITY_SLEEPNVML_VGPU_VM_COMPATIBILITY_LIVENVML_VGPU_COMPATIBILITY_LIMIT_NONENVML_VGPU_COMPATIBILITY_LIMIT_HOST_DRIVERNVML_VGPU_COMPATIBILITY_LIMIT_GUEST_DRIVERNVML_VGPU_COMPATIBILITY_LIMIT_GPUNVML_VGPU_COMPATIBILITY_LIMIT_OTHERNVML_HOST_VGPU_MODE_NON_SRIOVNVML_HOST_VGPU_MODE_SRIOVNVML_CC_ACCEPTING_CLIENT_REQUESTS_FALSENVML_CC_ACCEPTING_CLIENT_REQUESTS_TRUENVML_CC_SYSTEM_GPUS_CC_NOT_CAPABLENVML_CC_SYSTEM_GPUS_CC_CAPABLENVML_CC_SYSTEM_CPU_CAPS_NONENVML_CC_SYSTEM_CPU_CAPS_AMD_SEVNVML_CC_SYSTEM_CPU_CAPS_INTEL_TDXNVML_CC_SYSTEM_CPU_CAPS_AMD_SEV_SNPNVML_CC_SYSTEM_CPU_CAPS_AMD_SNP_VTOMNVML_CC_SYSTEM_DEVTOOLS_MODE_OFFNVML_CC_SYSTEM_DEVTOOLS_MODE_ONNVML_CC_SYSTEM_MULTIGPU_NONENVML_CC_SYSTEM_MULTIGPU_PROTECTED_PCIENVML_CC_SYSTEM_MULTIGPU_NVLENVML_CC_SYSTEM_ENVIRONMENT_UNAVAILABLENVML_CC_SYSTEM_ENVIRONMENT_SIMNVML_CC_SYSTEM_ENVIRONMENT_PRODNVML_CC_SYSTEM_FEATURE_DISABLEDNVML_CC_SYSTEM_FEATURE_ENABLEDNVML_CC_KEY_ROTATION_THRESH_ATTACKER_ADVANTAGE_MINNVML_CC_KEY_ROTATION_THRESH_ATTACKER_ADVANTAGE_MAXNVML_GSP_FIRMWARE_VERSION_BUF_SIZENVML_CPER_ACCESS_TYPE_GPUNVML_CPER_CURSOR_HANDLE_INITNVML_PROCESS_MODE_COMPUTENVML_PROCESS_MODE_GRAPHICSNVML_PROCESS_MODE_MPSNVML_PROCESS_MODE_ALLNVML_PROCESS_MODE_MAXNVML_NVLINK_TOTAL_SUPPORTED_BW_MODESNVML_VGPU_PGPU_HETEROGENEOUS_MODENVML_VGPU_PGPU_HOMOGENEOUS_MODENVML_GRID_LICENSE_STATE_UNKNOWNNVML_GRID_LICENSE_STATE_UNINITIALIZEDNVML_GRID_LICENSE_STATE_UNLICENSED_UNRESTRICTEDNVML_GRID_LICENSE_STATE_UNLICENSED_RESTRICTEDNVML_GRID_LICENSE_STATE_UNLICENSEDNVML_GRID_LICENSE_STATE_LICENSEDNVML_DEVICE_UUID_ASCII_LENNVML_DEVICE_UUID_BINARY_LENNVML_UUID_TYPE_NONENVML_UUID_TYPE_ASCIINVML_UUID_TYPE_BINARYNVML_NVLINK_FIRMWARE_UCODE_TYPE_MSENVML_NVLINK_FIRMWARE_UCODE_TYPE_NETIRNVML_NVLINK_FIRMWARE_UCODE_TYPE_NETIR_UPHYNVML_NVLINK_FIRMWARE_UCODE_TYPE_NETIR_CLNNVML_NVLINK_FIRMWARE_UCODE_TYPE_NETIR_DLNNVML_NVLINK_FIRMWARE_VERSION_LENGTHNVML_PRM_DATA_MAX_SIZENVML_DEVICE_ADDRESSING_MODE_NONENVML_DEVICE_ADDRESSING_MODE_HMMNVML_DEVICE_ADDRESSING_MODE_ATSNVML_PRM_COUNTER_ID_NONENVML_PRM_COUNTER_ID_PPCNT_PHYSICAL_LAYER_CTRS_LINK_DOWN_EVENTSNVML_PRM_COUNTER_ID_PPCNT_PHYSICAL_LAYER_CTRS_SUCCESSFUL_RECOVERY_EVENTSNVML_PRM_COUNTER_ID_PPCNT_RECOVERY_CTRS_TOTAL_SUCCESSFUL_RECOVERY_EVENTSNVML_PRM_COUNTER_ID_PPCNT_RECOVERY_CTRS_TIME_SINCE_LAST_RECOVERYNVML_PRM_COUNTER_ID_PPCNT_RECOVERY_CTRS_TIME_BETWEEN_LAST_TWO_RECOVERIESNVML_PRM_COUNTER_ID_PPCNT_PORTCOUNTERS_PORT_XMIT_WAITNVML_PRM_COUNTER_ID_PPCNT_PLR_RCV_CODESNVML_PRM_COUNTER_ID_PPCNT_PLR_RCV_CODE_ERRNVML_PRM_COUNTER_ID_PPCNT_PLR_RCV_UNCORRECTABLE_CODENVML_PRM_COUNTER_ID_PPCNT_PLR_XMIT_CODESNVML_PRM_COUNTER_ID_PPCNT_PLR_XMIT_RETRY_CODESNVML_PRM_COUNTER_ID_PPCNT_PLR_XMIT_RETRY_EVENTSNVML_PRM_COUNTER_ID_PPCNT_PLR_SYNC_EVENTSNVML_PRM_COUNTER_ID_PPRM_OPER_RECOVERYNVML_VGPU_SCHEDULER_POLICY_UNKNOWNNVML_VGPU_SCHEDULER_POLICY_BEST_EFFORTNVML_VGPU_SCHEDULER_POLICY_EQUAL_SHARENVML_VGPU_SCHEDULER_POLICY_FIXED_SHARENVML_SUPPORTED_VGPU_SCHEDULER_POLICY_COUNTNVML_SCHEDULER_SW_MAX_LOG_ENTRIESNVML_VGPU_SCHEDULER_ARR_DEFAULTNVML_VGPU_SCHEDULER_ARR_DISABLENVML_VGPU_SCHEDULER_ARR_ENABLENVML_VGPU_SCHEDULER_ENGINE_TYPE_GRAPHICSNVML_VGPU_SCHEDULER_ENGINE_TYPE_NVENC1NVML_VGPU_SCHEDULER_ENGINE_TYPE_NVENC0NVML_DEVICE_MIG_DISABLENVML_DEVICE_MIG_ENABLENVML_GPU_INSTANCE_PROFILE_1_SLICENVML_GPU_INSTANCE_PROFILE_2_SLICENVML_GPU_INSTANCE_PROFILE_3_SLICENVML_GPU_INSTANCE_PROFILE_4_SLICENVML_GPU_INSTANCE_PROFILE_7_SLICENVML_GPU_INSTANCE_PROFILE_8_SLICENVML_GPU_INSTANCE_PROFILE_6_SLICENVML_GPU_INSTANCE_PROFILE_1_SLICE_REV1NVML_GPU_INSTANCE_PROFILE_2_SLICE_REV1NVML_GPU_INSTANCE_PROFILE_1_SLICE_REV2NVML_GPU_INSTANCE_PROFILE_1_SLICE_GFXNVML_GPU_INSTANCE_PROFILE_2_SLICE_GFXNVML_GPU_INSTANCE_PROFILE_4_SLICE_GFXNVML_GPU_INSTANCE_PROFILE_1_SLICE_NO_MENVML_GPU_INSTANCE_PROFILE_2_SLICE_NO_MENVML_GPU_INSTANCE_PROFILE_1_SLICE_ALL_MENVML_GPU_INSTANCE_PROFILE_2_SLICE_ALL_MENVML_GPU_INSTANCE_PROFILE_3_SLICE_GFXNVML_GPU_INSTANCE_PROFILE_COUNTNVML_COMPUTE_INSTANCE_PROFILE_1_SLICENVML_COMPUTE_INSTANCE_PROFILE_2_SLICENVML_COMPUTE_INSTANCE_PROFILE_3_SLICENVML_COMPUTE_INSTANCE_PROFILE_4_SLICENVML_COMPUTE_INSTANCE_PROFILE_7_SLICENVML_COMPUTE_INSTANCE_PROFILE_8_SLICENVML_COMPUTE_INSTANCE_PROFILE_6_SLICENVML_COMPUTE_INSTANCE_PROFILE_1_SLICE_REV1NVML_COMPUTE_INSTANCE_PROFILE_7_SLICE_NVLNVML_COMPUTE_INSTANCE_PROFILE_COUNTNVML_COMPUTE_INSTANCE_ENGINE_PROFILE_SHAREDNVML_COMPUTE_INSTANCE_ENGINE_PROFILE_COUNTNVML_MAX_GPU_UTILIZATIONSNVML_GPU_UTILIZATION_DOMAIN_GPUNVML_GPU_UTILIZATION_DOMAIN_FBNVML_GPU_UTILIZATION_DOMAIN_VIDNVML_GPU_UTILIZATION_DOMAIN_BUSNVML_MAX_THERMAL_SENSORS_PER_GPUNVML_THERMAL_TARGET_NONENVML_THERMAL_TARGET_GPUNVML_THERMAL_TARGET_MEMORYNVML_THERMAL_TARGET_POWER_SUPPLYNVML_THERMAL_TARGET_BOARDNVML_THERMAL_TARGET_VCD_BOARDNVML_THERMAL_TARGET_VCD_INLETNVML_THERMAL_TARGET_VCD_OUTLETNVML_THERMAL_TARGET_ALLNVML_THERMAL_TARGET_UNKNOWNNVML_THERMAL_CONTROLLER_NONENVML_THERMAL_CONTROLLER_GPU_INTERNALNVML_THERMAL_CONTROLLER_ADM1032NVML_THERMAL_CONTROLLER_ADT7461NVML_THERMAL_CONTROLLER_MAX6649NVML_THERMAL_CONTROLLER_MAX1617NVML_THERMAL_CONTROLLER_LM99NVML_THERMAL_CONTROLLER_LM89NVML_THERMAL_CONTROLLER_LM64NVML_THERMAL_CONTROLLER_G781NVML_THERMAL_CONTROLLER_ADT7473NVML_THERMAL_CONTROLLER_SBMAX6649NVML_THERMAL_CONTROLLER_VBIOSEVTNVML_THERMAL_CONTROLLER_OSNVML_THERMAL_CONTROLLER_NVSYSCON_CANOASNVML_THERMAL_CONTROLLER_NVSYSCON_E551NVML_THERMAL_CONTROLLER_MAX6649RNVML_THERMAL_CONTROLLER_ADT7473SNVML_THERMAL_CONTROLLER_UNKNOWNNVML_THERMAL_COOLER_SIGNAL_NONENVML_THERMAL_COOLER_SIGNAL_TOGGLENVML_THERMAL_COOLER_SIGNAL_VARIABLENVML_THERMAL_COOLER_SIGNAL_COUNTNVML_THERMAL_COOLER_TARGET_NONENVML_THERMAL_COOLER_TARGET_GPUNVML_THERMAL_COOLER_TARGET_MEMORYNVML_THERMAL_COOLER_TARGET_POWER_SUPPLYNVML_THERMAL_COOLER_TARGET_GPU_RELATEDNVML_GPU_CERT_CHAIN_SIZENVML_GPU_ATTESTATION_CERT_CHAIN_SIZENVML_CC_GPU_CEC_NONCE_SIZENVML_CC_GPU_ATTESTATION_REPORT_SIZENVML_CC_GPU_CEC_ATTESTATION_REPORT_SIZENVML_CC_CEC_ATTESTATION_REPORT_NOT_PRESENTNVML_CC_CEC_ATTESTATION_REPORT_PRESENTNVML_POWER_MIZER_MODE_ADAPTIVENVML_POWER_MIZER_MODE_PREFER_MAXIMUM_PERFORMANCENVML_POWER_MIZER_MODE_AUTONVML_POWER_MIZER_MODE_PREFER_CONSISTENT_PERFORMANCENVML_GPM_METRIC_GRAPHICS_UTILNVML_GPM_METRIC_SM_UTILNVML_GPM_METRIC_SM_OCCUPANCYNVML_GPM_METRIC_INTEGER_UTILNVML_GPM_METRIC_ANY_TENSOR_UTILNVML_GPM_METRIC_DFMA_TENSOR_UTILNVML_GPM_METRIC_HMMA_TENSOR_UTILNVML_GPM_METRIC_DMMA_TENSOR_UTILNVML_GPM_METRIC_IMMA_TENSOR_UTILNVML_GPM_METRIC_DRAM_BW_UTILNVML_GPM_METRIC_FP64_UTILNVML_GPM_METRIC_FP32_UTILNVML_GPM_METRIC_FP16_UTILNVML_GPM_METRIC_PCIE_TX_PER_SECNVML_GPM_METRIC_PCIE_RX_PER_SECNVML_GPM_METRIC_NVDEC_0_UTILNVML_GPM_METRIC_NVDEC_1_UTILNVML_GPM_METRIC_NVDEC_2_UTILNVML_GPM_METRIC_NVDEC_3_UTILNVML_GPM_METRIC_NVDEC_4_UTILNVML_GPM_METRIC_NVDEC_5_UTILNVML_GPM_METRIC_NVDEC_6_UTILNVML_GPM_METRIC_NVDEC_7_UTILNVML_GPM_METRIC_NVJPG_0_UTILNVML_GPM_METRIC_NVJPG_1_UTILNVML_GPM_METRIC_NVJPG_2_UTILNVML_GPM_METRIC_NVJPG_3_UTILNVML_GPM_METRIC_NVJPG_4_UTILNVML_GPM_METRIC_NVJPG_5_UTILNVML_GPM_METRIC_NVJPG_6_UTILNVML_GPM_METRIC_NVJPG_7_UTILNVML_GPM_METRIC_NVOFA_0_UTILNVML_GPM_METRIC_NVOFA_1_UTILNVML_GPM_METRIC_NVLINK_TOTAL_RX_PER_SECNVML_GPM_METRIC_NVLINK_TOTAL_TX_PER_SECNVML_GPM_METRIC_NVLINK_L0_RX_PER_SECNVML_GPM_METRIC_NVLINK_L0_TX_PER_SECNVML_GPM_METRIC_NVLINK_L1_RX_PER_SECNVML_GPM_METRIC_NVLINK_L1_TX_PER_SECNVML_GPM_METRIC_NVLINK_L2_RX_PER_SECNVML_GPM_METRIC_NVLINK_L2_TX_PER_SECNVML_GPM_METRIC_NVLINK_L3_RX_PER_SECNVML_GPM_METRIC_NVLINK_L3_TX_PER_SECNVML_GPM_METRIC_NVLINK_L4_RX_PER_SECNVML_GPM_METRIC_NVLINK_L4_TX_PER_SECNVML_GPM_METRIC_NVLINK_L5_RX_PER_SECNVML_GPM_METRIC_NVLINK_L5_TX_PER_SECNVML_GPM_METRIC_NVLINK_L6_RX_PER_SECNVML_GPM_METRIC_NVLINK_L6_TX_PER_SECNVML_GPM_METRIC_NVLINK_L7_RX_PER_SECNVML_GPM_METRIC_NVLINK_L7_TX_PER_SECNVML_GPM_METRIC_NVLINK_L8_RX_PER_SECNVML_GPM_METRIC_NVLINK_L8_TX_PER_SECNVML_GPM_METRIC_NVLINK_L9_RX_PER_SECNVML_GPM_METRIC_NVLINK_L9_TX_PER_SECNVML_GPM_METRIC_NVLINK_L10_RX_PER_SECNVML_GPM_METRIC_NVLINK_L10_TX_PER_SECNVML_GPM_METRIC_NVLINK_L11_RX_PER_SECNVML_GPM_METRIC_NVLINK_L11_TX_PER_SECNVML_GPM_METRIC_NVLINK_L12_RX_PER_SECNVML_GPM_METRIC_NVLINK_L12_TX_PER_SECNVML_GPM_METRIC_NVLINK_L13_RX_PER_SECNVML_GPM_METRIC_NVLINK_L13_TX_PER_SECNVML_GPM_METRIC_NVLINK_L14_RX_PER_SECNVML_GPM_METRIC_NVLINK_L14_TX_PER_SECNVML_GPM_METRIC_NVLINK_L15_RX_PER_SECNVML_GPM_METRIC_NVLINK_L15_TX_PER_SECNVML_GPM_METRIC_NVLINK_L16_RX_PER_SECNVML_GPM_METRIC_NVLINK_L16_TX_PER_SECNVML_GPM_METRIC_NVLINK_L17_RX_PER_SECNVML_GPM_METRIC_NVLINK_L17_TX_PER_SECNVML_GPM_METRIC_C2C_TOTAL_TX_PER_SECNVML_GPM_METRIC_C2C_TOTAL_RX_PER_SECNVML_GPM_METRIC_C2C_DATA_TX_PER_SECNVML_GPM_METRIC_C2C_DATA_RX_PER_SECNVML_GPM_METRIC_C2C_LINK0_TOTAL_TX_PER_SECNVML_GPM_METRIC_C2C_LINK0_TOTAL_RX_PER_SECNVML_GPM_METRIC_C2C_LINK0_DATA_TX_PER_SECNVML_GPM_METRIC_C2C_LINK0_DATA_RX_PER_SECNVML_GPM_METRIC_C2C_LINK1_TOTAL_TX_PER_SECNVML_GPM_METRIC_C2C_LINK1_TOTAL_RX_PER_SECNVML_GPM_METRIC_C2C_LINK1_DATA_TX_PER_SECNVML_GPM_METRIC_C2C_LINK1_DATA_RX_PER_SECNVML_GPM_METRIC_C2C_LINK2_TOTAL_TX_PER_SECNVML_GPM_METRIC_C2C_LINK2_TOTAL_RX_PER_SECNVML_GPM_METRIC_C2C_LINK2_DATA_TX_PER_SECNVML_GPM_METRIC_C2C_LINK2_DATA_RX_PER_SECNVML_GPM_METRIC_C2C_LINK3_TOTAL_TX_PER_SECNVML_GPM_METRIC_C2C_LINK3_TOTAL_RX_PER_SECNVML_GPM_METRIC_C2C_LINK3_DATA_TX_PER_SECNVML_GPM_METRIC_C2C_LINK3_DATA_RX_PER_SECNVML_GPM_METRIC_C2C_LINK4_TOTAL_TX_PER_SECNVML_GPM_METRIC_C2C_LINK4_TOTAL_RX_PER_SECNVML_GPM_METRIC_C2C_LINK4_DATA_TX_PER_SECNVML_GPM_METRIC_C2C_LINK4_DATA_RX_PER_SECNVML_GPM_METRIC_C2C_LINK5_TOTAL_TX_PER_SECNVML_GPM_METRIC_C2C_LINK5_TOTAL_RX_PER_SECNVML_GPM_METRIC_C2C_LINK5_DATA_TX_PER_SECNVML_GPM_METRIC_C2C_LINK5_DATA_RX_PER_SECNVML_GPM_METRIC_C2C_LINK6_TOTAL_TX_PER_SECNVML_GPM_METRIC_C2C_LINK6_TOTAL_RX_PER_SECNVML_GPM_METRIC_C2C_LINK6_DATA_TX_PER_SECNVML_GPM_METRIC_C2C_LINK6_DATA_RX_PER_SECNVML_GPM_METRIC_C2C_LINK7_TOTAL_TX_PER_SECNVML_GPM_METRIC_C2C_LINK7_TOTAL_RX_PER_SECNVML_GPM_METRIC_C2C_LINK7_DATA_TX_PER_SECNVML_GPM_METRIC_C2C_LINK7_DATA_RX_PER_SECNVML_GPM_METRIC_C2C_LINK8_TOTAL_TX_PER_SECNVML_GPM_METRIC_C2C_LINK8_TOTAL_RX_PER_SECNVML_GPM_METRIC_C2C_LINK8_DATA_TX_PER_SECNVML_GPM_METRIC_C2C_LINK8_DATA_RX_PER_SECNVML_GPM_METRIC_C2C_LINK9_TOTAL_TX_PER_SECNVML_GPM_METRIC_C2C_LINK9_TOTAL_RX_PER_SECNVML_GPM_METRIC_C2C_LINK9_DATA_TX_PER_SECNVML_GPM_METRIC_C2C_LINK9_DATA_RX_PER_SECNVML_GPM_METRIC_C2C_LINK10_TOTAL_TX_PER_SECNVML_GPM_METRIC_C2C_LINK10_TOTAL_RX_PER_SECNVML_GPM_METRIC_C2C_LINK10_DATA_TX_PER_SECNVML_GPM_METRIC_C2C_LINK10_DATA_RX_PER_SECNVML_GPM_METRIC_C2C_LINK11_TOTAL_TX_PER_SECNVML_GPM_METRIC_C2C_LINK11_TOTAL_RX_PER_SECNVML_GPM_METRIC_C2C_LINK11_DATA_TX_PER_SECNVML_GPM_METRIC_C2C_LINK11_DATA_RX_PER_SECNVML_GPM_METRIC_C2C_LINK12_TOTAL_TX_PER_SECNVML_GPM_METRIC_C2C_LINK12_TOTAL_RX_PER_SECNVML_GPM_METRIC_C2C_LINK12_DATA_TX_PER_SECNVML_GPM_METRIC_C2C_LINK12_DATA_RX_PER_SECNVML_GPM_METRIC_C2C_LINK13_TOTAL_TX_PER_SECNVML_GPM_METRIC_C2C_LINK13_TOTAL_RX_PER_SECNVML_GPM_METRIC_C2C_LINK13_DATA_TX_PER_SECNVML_GPM_METRIC_C2C_LINK13_DATA_RX_PER_SECNVML_GPM_METRIC_HOSTMEM_CACHE_HITNVML_GPM_METRIC_HOSTMEM_CACHE_MISSNVML_GPM_METRIC_PEERMEM_CACHE_HITNVML_GPM_METRIC_PEERMEM_CACHE_MISSNVML_GPM_METRIC_DRAM_CACHE_HITNVML_GPM_METRIC_DRAM_CACHE_MISSNVML_GPM_METRIC_NVENC_0_UTILNVML_GPM_METRIC_NVENC_1_UTILNVML_GPM_METRIC_NVENC_2_UTILNVML_GPM_METRIC_NVENC_3_UTILNVML_GPM_METRIC_GR0_CTXSW_CYCLES_ELAPSEDNVML_GPM_METRIC_GR0_CTXSW_CYCLES_ACTIVENVML_GPM_METRIC_GR0_CTXSW_REQUESTSNVML_GPM_METRIC_GR0_CTXSW_CYCLES_PER_REQNVML_GPM_METRIC_GR0_CTXSW_ACTIVE_PCTNVML_GPM_METRIC_GR1_CTXSW_CYCLES_ELAPSEDNVML_GPM_METRIC_GR1_CTXSW_CYCLES_ACTIVENVML_GPM_METRIC_GR1_CTXSW_REQUESTSNVML_GPM_METRIC_GR1_CTXSW_CYCLES_PER_REQNVML_GPM_METRIC_GR1_CTXSW_ACTIVE_PCTNVML_GPM_METRIC_GR2_CTXSW_CYCLES_ELAPSEDNVML_GPM_METRIC_GR2_CTXSW_CYCLES_ACTIVENVML_GPM_METRIC_GR2_CTXSW_REQUESTSNVML_GPM_METRIC_GR2_CTXSW_CYCLES_PER_REQNVML_GPM_METRIC_GR2_CTXSW_ACTIVE_PCTNVML_GPM_METRIC_GR3_CTXSW_CYCLES_ELAPSEDNVML_GPM_METRIC_GR3_CTXSW_CYCLES_ACTIVENVML_GPM_METRIC_GR3_CTXSW_REQUESTSNVML_GPM_METRIC_GR3_CTXSW_CYCLES_PER_REQNVML_GPM_METRIC_GR3_CTXSW_ACTIVE_PCTNVML_GPM_METRIC_GR4_CTXSW_CYCLES_ELAPSEDNVML_GPM_METRIC_GR4_CTXSW_CYCLES_ACTIVENVML_GPM_METRIC_GR4_CTXSW_REQUESTSNVML_GPM_METRIC_GR4_CTXSW_CYCLES_PER_REQNVML_GPM_METRIC_GR4_CTXSW_ACTIVE_PCTNVML_GPM_METRIC_GR5_CTXSW_CYCLES_ELAPSEDNVML_GPM_METRIC_GR5_CTXSW_CYCLES_ACTIVENVML_GPM_METRIC_GR5_CTXSW_REQUESTSNVML_GPM_METRIC_GR5_CTXSW_CYCLES_PER_REQNVML_GPM_METRIC_GR5_CTXSW_ACTIVE_PCTNVML_GPM_METRIC_GR6_CTXSW_CYCLES_ELAPSEDNVML_GPM_METRIC_GR6_CTXSW_CYCLES_ACTIVENVML_GPM_METRIC_GR6_CTXSW_REQUESTSNVML_GPM_METRIC_GR6_CTXSW_CYCLES_PER_REQNVML_GPM_METRIC_GR6_CTXSW_ACTIVE_PCTNVML_GPM_METRIC_GR7_CTXSW_CYCLES_ELAPSEDNVML_GPM_METRIC_GR7_CTXSW_CYCLES_ACTIVENVML_GPM_METRIC_GR7_CTXSW_REQUESTSNVML_GPM_METRIC_GR7_CTXSW_CYCLES_PER_REQNVML_GPM_METRIC_GR7_CTXSW_ACTIVE_PCTNVML_GPM_METRIC_NVLINK_L18_RX_PER_SECNVML_GPM_METRIC_NVLINK_L18_TX_PER_SECNVML_GPM_METRIC_NVLINK_L19_RX_PER_SECNVML_GPM_METRIC_NVLINK_L19_TX_PER_SECNVML_GPM_METRIC_NVLINK_L20_RX_PER_SECNVML_GPM_METRIC_NVLINK_L20_TX_PER_SECNVML_GPM_METRIC_NVLINK_L21_RX_PER_SECNVML_GPM_METRIC_NVLINK_L21_TX_PER_SECNVML_GPM_METRIC_NVLINK_L22_RX_PER_SECNVML_GPM_METRIC_NVLINK_L22_TX_PER_SECNVML_GPM_METRIC_NVLINK_L23_RX_PER_SECNVML_GPM_METRIC_NVLINK_L23_TX_PER_SECNVML_GPM_METRIC_NVLINK_L24_RX_PER_SECNVML_GPM_METRIC_NVLINK_L24_TX_PER_SECNVML_GPM_METRIC_NVLINK_L25_RX_PER_SECNVML_GPM_METRIC_NVLINK_L25_TX_PER_SECNVML_GPM_METRIC_NVLINK_L26_RX_PER_SECNVML_GPM_METRIC_NVLINK_L26_TX_PER_SECNVML_GPM_METRIC_NVLINK_L27_RX_PER_SECNVML_GPM_METRIC_NVLINK_L27_TX_PER_SECNVML_GPM_METRIC_NVLINK_L28_RX_PER_SECNVML_GPM_METRIC_NVLINK_L28_TX_PER_SECNVML_GPM_METRIC_NVLINK_L29_RX_PER_SECNVML_GPM_METRIC_NVLINK_L29_TX_PER_SECNVML_GPM_METRIC_NVLINK_L30_RX_PER_SECNVML_GPM_METRIC_NVLINK_L30_TX_PER_SECNVML_GPM_METRIC_NVLINK_L31_RX_PER_SECNVML_GPM_METRIC_NVLINK_L31_TX_PER_SECNVML_GPM_METRIC_NVLINK_L32_RX_PER_SECNVML_GPM_METRIC_NVLINK_L32_TX_PER_SECNVML_GPM_METRIC_NVLINK_L33_RX_PER_SECNVML_GPM_METRIC_NVLINK_L33_TX_PER_SECNVML_GPM_METRIC_NVLINK_L34_RX_PER_SECNVML_GPM_METRIC_NVLINK_L34_TX_PER_SECNVML_GPM_METRIC_NVLINK_L35_RX_PER_SECNVML_GPM_METRIC_NVLINK_L35_TX_PER_SECNVML_GPM_METRIC_SM_CYCLES_ELAPSEDNVML_GPM_METRIC_SM_CYCLES_ACTIVENVML_GPM_METRIC_MMA_CYCLES_ACTIVENVML_GPM_METRIC_DMMA_CYCLES_ACTIVENVML_GPM_METRIC_HMMA_CYCLES_ACTIVENVML_GPM_METRIC_IMMA_CYCLES_ACTIVENVML_GPM_METRIC_DFMA_CYCLES_ACTIVENVML_GPM_METRIC_PCIE_TXNVML_GPM_METRIC_PCIE_RXNVML_GPM_METRIC_INTEGER_CYCLES_ACTIVENVML_GPM_METRIC_FP64_CYCLES_ACTIVENVML_GPM_METRIC_FP32_CYCLES_ACTIVENVML_GPM_METRIC_FP16_CYCLES_ACTIVENVML_GPM_METRIC_NVLINK_L0_RXNVML_GPM_METRIC_NVLINK_L0_TXNVML_GPM_METRIC_NVLINK_L1_RXNVML_GPM_METRIC_NVLINK_L1_TXNVML_GPM_METRIC_NVLINK_L2_RXNVML_GPM_METRIC_NVLINK_L2_TXNVML_GPM_METRIC_NVLINK_L3_RXNVML_GPM_METRIC_NVLINK_L3_TXNVML_GPM_METRIC_NVLINK_L4_RXNVML_GPM_METRIC_NVLINK_L4_TXNVML_GPM_METRIC_NVLINK_L5_RXNVML_GPM_METRIC_NVLINK_L5_TXNVML_GPM_METRIC_NVLINK_L6_RXNVML_GPM_METRIC_NVLINK_L6_TXNVML_GPM_METRIC_NVLINK_L7_RXNVML_GPM_METRIC_NVLINK_L7_TXNVML_GPM_METRIC_NVLINK_L8_RXNVML_GPM_METRIC_NVLINK_L8_TXNVML_GPM_METRIC_NVLINK_L9_RXNVML_GPM_METRIC_NVLINK_L9_TXNVML_GPM_METRIC_NVLINK_L10_RXNVML_GPM_METRIC_NVLINK_L10_TXNVML_GPM_METRIC_NVLINK_L11_RXNVML_GPM_METRIC_NVLINK_L11_TXNVML_GPM_METRIC_NVLINK_L12_RXNVML_GPM_METRIC_NVLINK_L12_TXNVML_GPM_METRIC_NVLINK_L13_RXNVML_GPM_METRIC_NVLINK_L13_TXNVML_GPM_METRIC_NVLINK_L14_RXNVML_GPM_METRIC_NVLINK_L14_TXNVML_GPM_METRIC_NVLINK_L15_RXNVML_GPM_METRIC_NVLINK_L15_TXNVML_GPM_METRIC_NVLINK_L16_RXNVML_GPM_METRIC_NVLINK_L16_TXNVML_GPM_METRIC_NVLINK_L17_RXNVML_GPM_METRIC_NVLINK_L17_TXNVML_GPM_METRIC_NVLINK_L18_RXNVML_GPM_METRIC_NVLINK_L18_TXNVML_GPM_METRIC_NVLINK_L19_RXNVML_GPM_METRIC_NVLINK_L19_TXNVML_GPM_METRIC_NVLINK_L20_RXNVML_GPM_METRIC_NVLINK_L20_TXNVML_GPM_METRIC_NVLINK_L21_RXNVML_GPM_METRIC_NVLINK_L21_TXNVML_GPM_METRIC_NVLINK_L22_RXNVML_GPM_METRIC_NVLINK_L22_TXNVML_GPM_METRIC_NVLINK_L23_RXNVML_GPM_METRIC_NVLINK_L23_TXNVML_GPM_METRIC_NVLINK_L24_RXNVML_GPM_METRIC_NVLINK_L24_TXNVML_GPM_METRIC_NVLINK_L25_RXNVML_GPM_METRIC_NVLINK_L25_TXNVML_GPM_METRIC_NVLINK_L26_RXNVML_GPM_METRIC_NVLINK_L26_TXNVML_GPM_METRIC_NVLINK_L27_RXNVML_GPM_METRIC_NVLINK_L27_TXNVML_GPM_METRIC_NVLINK_L28_RXNVML_GPM_METRIC_NVLINK_L28_TXNVML_GPM_METRIC_NVLINK_L29_RXNVML_GPM_METRIC_NVLINK_L29_TXNVML_GPM_METRIC_NVLINK_L30_RXNVML_GPM_METRIC_NVLINK_L30_TXNVML_GPM_METRIC_NVLINK_L31_RXNVML_GPM_METRIC_NVLINK_L31_TXNVML_GPM_METRIC_NVLINK_L32_RXNVML_GPM_METRIC_NVLINK_L32_TXNVML_GPM_METRIC_NVLINK_L33_RXNVML_GPM_METRIC_NVLINK_L33_TXNVML_GPM_METRIC_NVLINK_L34_RXNVML_GPM_METRIC_NVLINK_L34_TXNVML_GPM_METRIC_NVLINK_L35_RXNVML_GPM_METRIC_NVLINK_L35_TXNVML_GPM_METRIC_MAXNVML_GPM_METRICS_GET_VERSIONNVML_GPM_SUPPORT_VERSIONNVML_NVLINK_POWER_STATE_HIGH_SPEEDNVML_NVLINK_POWER_STATE_LOWNVML_NVLINK_LOW_POWER_THRESHOLD_MINNVML_NVLINK_LOW_POWER_THRESHOLD_MAXNVML_NVLINK_LOW_POWER_THRESHOLD_RESETNVML_NVLINK_LOW_POWER_THRESHOLD_DEFAULTNVML_GPU_FABRIC_UUID_LENNVML_GPU_FABRIC_STATE_NOT_SUPPORTEDNVML_GPU_FABRIC_STATE_NOT_STARTEDNVML_GPU_FABRIC_STATE_IN_PROGRESSNVML_GPU_FABRIC_STATE_COMPLETEDNVML_GPU_FABRIC_HEALTH_MASK_DEGRADED_BW_NOT_SUPPORTEDNVML_GPU_FABRIC_HEALTH_MASK_DEGRADED_BW_TRUENVML_GPU_FABRIC_HEALTH_MASK_DEGRADED_BW_FALSENVML_GPU_FABRIC_HEALTH_MASK_SHIFT_DEGRADED_BWNVML_GPU_FABRIC_HEALTH_MASK_WIDTH_DEGRADED_BWNVML_GPU_FABRIC_HEALTH_MASK_ROUTE_RECOVERY_NOT_SUPPORTEDNVML_GPU_FABRIC_HEALTH_MASK_ROUTE_RECOVERY_TRUENVML_GPU_FABRIC_HEALTH_MASK_ROUTE_RECOVERY_FALSENVML_GPU_FABRIC_HEALTH_MASK_SHIFT_ROUTE_RECOVERYNVML_GPU_FABRIC_HEALTH_MASK_WIDTH_ROUTE_RECOVERYNVML_GPU_FABRIC_HEALTH_MASK_ROUTE_UNHEALTHY_NOT_SUPPORTEDNVML_GPU_FABRIC_HEALTH_MASK_ROUTE_UNHEALTHY_TRUENVML_GPU_FABRIC_HEALTH_MASK_ROUTE_UNHEALTHY_FALSENVML_GPU_FABRIC_HEALTH_MASK_SHIFT_ROUTE_UNHEALTHYNVML_GPU_FABRIC_HEALTH_MASK_WIDTH_ROUTE_UNHEALTHYNVML_GPU_FABRIC_HEALTH_MASK_ACCESS_TIMEOUT_RECOVERY_NOT_SUPPORTEDNVML_GPU_FABRIC_HEALTH_MASK_ACCESS_TIMEOUT_RECOVERY_TRUENVML_GPU_FABRIC_HEALTH_MASK_ACCESS_TIMEOUT_RECOVERY_FALSENVML_GPU_FABRIC_HEALTH_MASK_SHIFT_ACCESS_TIMEOUT_RECOVERYNVML_GPU_FABRIC_HEALTH_MASK_WIDTH_ACCESS_TIMEOUT_RECOVERYNVML_GPU_FABRIC_HEALTH_MASK_INCORRECT_CONFIGURATION_NOT_SUPPORTEDNVML_GPU_FABRIC_HEALTH_MASK_INCORRECT_CONFIGURATION_NONENVML_GPU_FABRIC_HEALTH_MASK_INCORRECT_CONFIGURATION_INCORRECT_SYSGUIDNVML_GPU_FABRIC_HEALTH_MASK_INCORRECT_CONFIGURATION_INCORRECT_CHASSIS_SNNVML_GPU_FABRIC_HEALTH_MASK_INCORRECT_CONFIGURATION_NO_PARTITIONNVML_GPU_FABRIC_HEALTH_MASK_INCORRECT_CONFIGURATION_INSUFFICIENT_NVLINKSNVML_GPU_FABRIC_HEALTH_MASK_INCORRECT_CONFIGURATION_INCOMPATIBLE_GPU_FWNVML_GPU_FABRIC_HEALTH_MASK_INCORRECT_CONFIURATION_INVALID_LOCATIONNVML_GPU_FABRIC_HEALTH_MASK_INCORRECT_CONFIGURATION_INVALID_LOCATIONNVML_GPU_FABRIC_HEALTH_MASK_INCORRECT_CONFIGURATION_GPU_STATE_INVALIDNVML_GPU_FABRIC_HEALTH_MASK_SHIFT_INCORRECT_CONFIGURATIONNVML_GPU_FABRIC_HEALTH_MASK_WIDTH_INCORRECT_CONFIGURATIONNVML_GPU_FABRIC_HEALTH_MASK_PARTITION_ASSIGNED_NOT_SUPPORTEDNVML_GPU_FABRIC_HEALTH_MASK_PARTITION_ASSIGNED_TRUENVML_GPU_FABRIC_HEALTH_MASK_PARTITION_ASSIGNED_FALSENVML_GPU_FABRIC_HEALTH_MASK_SHIFT_PARTITION_ASSIGNEDNVML_GPU_FABRIC_HEALTH_MASK_WIDTH_PARTITION_ASSIGNEDNVML_GPU_FABRIC_HEALTH_SUMMARY_NOT_SUPPORTEDNVML_GPU_FABRIC_HEALTH_SUMMARY_HEALTHYNVML_GPU_FABRIC_HEALTH_SUMMARY_UNHEALTHYNVML_GPU_FABRIC_HEALTH_SUMMARY_LIMITED_CAPACITYNVML_GPU_NVLINK_BW_MODE_FULLNVML_GPU_NVLINK_BW_MODE_OFFNVML_GPU_NVLINK_BW_MODE_MINNVML_GPU_NVLINK_BW_MODE_HALFNVML_GPU_NVLINK_BW_MODE_3QUARTERNVML_GPU_NVLINK_BW_MODE_COUNTNVML_POWER_SCOPE_GPUNVML_POWER_SCOPE_MODULENVML_POWER_SCOPE_MEMORYNVML_POWER_SCOPE_GPU_BASENVML_POWER_SCOPE_COUNTNVML_DEV_CAP_EGMNVML_DEVICE_HOSTNAME_BUFFER_SIZENVML_WORKLOAD_POWER_MAX_PROFILESNVML_POWER_PROFILE_MAX_PNVML_POWER_PROFILE_MAX_QNVML_POWER_PROFILE_COMPUTENVML_POWER_PROFILE_MEMORY_BOUNDNVML_POWER_PROFILE_NETWORKNVML_POWER_PROFILE_BALANCEDNVML_POWER_PROFILE_LLM_INFERENCENVML_POWER_PROFILE_LLM_TRAININGNVML_POWER_PROFILE_RBMNVML_POWER_PROFILE_DCPCIENVML_POWER_PROFILE_HMMA_SPARSENVML_POWER_PROFILE_HMMA_DENSENVML_POWER_PROFILE_SYNC_BALANCEDNVML_POWER_PROFILE_HPCNVML_POWER_PROFILE_MIGNVML_POWER_PROFILE_MAXNVML_POWER_PROFILE_OPERATION_CLEARNVML_POWER_PROFILE_OPERATION_SETNVML_POWER_PROFILE_OPERATION_SET_AND_OVERWRITENVML_POWER_PROFILE_OPERATION_MAXNVML_POWER_SMOOTHING_NUM_PROFILE_PARAMSNVML_POWER_SMOOTHING_MAX_NUM_PROFILESNVML_POWER_SMOOTHING_ADMIN_OVERRIDE_NOT_SETNVML_POWER_SMOOTHING_PROFILE_PARAM_PERCENT_TMP_FLOORNVML_POWER_SMOOTHING_PROFILE_PARAM_RAMP_UP_RATENVML_POWER_SMOOTHING_PROFILE_PARAM_RAMP_DOWN_RATENVML_POWER_SMOOTHING_PROFILE_PARAM_RAMP_DOWN_HYSTERESISNVML_POWER_SMOOTHING_PROFILE_PARAM_SECONDARY_POWER_FLOORNVML_POWER_SMOOTHING_PROFILE_PARAM_PRIMARY_FLOOR_ACT_WIN_MULTNVML_POWER_SMOOTHING_PROFILE_PARAM_PRIMARY_FLOOR_TAR_WIN_MULTNVML_POWER_SMOOTHING_PROFILE_PARAM_PRIMARY_FLOOR_ACT_OFFSETNVML_RUSD_POLL_NONENVML_RUSD_POLL_CLOCKNVML_RUSD_POLL_PERFNVML_RUSD_POLL_MEMORYNVML_RUSD_POLL_POWERNVML_RUSD_POLL_THERMALNVML_RUSD_POLL_PCINVML_RUSD_POLL_FANNVML_RUSD_POLL_PROC_UTILNVML_RUSD_POLL_ALL
- Functions and Exceptions
NVMLErrornvmlCheckReturn()nvmlInit()nvmlInitWithFlags()nvmlQuery()nvmlQueryFieldValues()nvmlShutdown()NVMLError_AlreadyInitializedNVMLError_ArgumentVersionMismatchNVMLError_CorruptedInforomNVMLError_DeprecatedNVMLError_DriverNotLoadedNVMLError_FreqNotSupportedNVMLError_FunctionNotFoundNVMLError_GpuIsLostNVMLError_GpuNotFoundNVMLError_InsufficientPowerNVMLError_InsufficientResourcesNVMLError_InsufficientSizeNVMLError_InvalidArgumentNVMLError_InvalidStateNVMLError_InUseNVMLError_IrqIssueNVMLError_LibraryNotFoundNVMLError_LibRmVersionMismatchNVMLError_MemoryNVMLError_NotFoundNVMLError_NotReadyNVMLError_NotSupportedNVMLError_NoDataNVMLError_NoPermissionNVMLError_OperatingSystemNVMLError_ResetRequiredNVMLError_ResetTypeNotSupportedNVMLError_TimeoutNVMLError_UninitializedNVMLError_UnknownNVMLError_VgpuEccNotSupportednvmlExceptionClass()nvmlStructToFriendlyObject()nvmlFriendlyObjectToStruct()nvmlDeviceReadWritePRM_v1()nvmlDeviceReadPRMCounters_v1()nvmlDeviceGetBBXTimeData_v1()nvmlSystemEventSetCreate()nvmlSystemEventSetFree()nvmlSystemRegisterEvents()nvmlSystemEventSetWait()nvmlDeviceGetCoolerInfo()nvmlErrorString()nvmlSystemGetNVMLVersion()nvmlSystemGetCudaDriverVersion()nvmlSystemGetCudaDriverVersion_v2()nvmlSystemGetProcessName()nvmlSystemGetDriverVersion()nvmlSystemGetHicVersion()nvmlSystemGetDriverBranch()nvmlSystemGetCPER_v1()nvmlUnitGetCount()nvmlUnitGetHandleByIndex()nvmlUnitGetUnitInfo()nvmlUnitGetLedState()nvmlUnitGetPsuInfo()nvmlUnitGetTemperature()nvmlUnitGetFanSpeedInfo()nvmlUnitGetDeviceCount()nvmlUnitGetDevices()nvmlDeviceGetCount()nvmlDeviceGetHandleByIndex()nvmlDeviceGetHandleBySerial()nvmlDeviceGetHandleByUUID()nvmlDeviceGetHandleByUUIDV()nvmlDeviceGetHandleByPciBusId()nvmlDeviceGetName()nvmlDeviceGetPerformanceModes()nvmlDeviceGetCurrentClockFreqs()nvmlDeviceGetBoardId()nvmlDeviceGetMultiGpuBoard()nvmlDeviceGetBrand()nvmlDeviceGetC2cModeInfoV1()nvmlDeviceGetC2cModeInfoV()nvmlDeviceGetBoardPartNumber()nvmlDeviceGetSerial()nvmlDeviceGetModuleId()nvmlDeviceGetMemoryAffinity()nvmlDeviceGetCpuAffinityWithinScope()nvmlDeviceGetCpuAffinity()nvmlDeviceSetCpuAffinity()nvmlDeviceClearCpuAffinity()nvmlDeviceGetNumaNodeId()nvmlDeviceGetAddressingMode()nvmlDeviceGetMinorNumber()nvmlDeviceGetUUID()nvmlDeviceGetInforomVersion()nvmlDeviceGetInforomImageVersion()nvmlDeviceGetInforomConfigurationChecksum()nvmlDeviceValidateInforom()nvmlDeviceGetLastBBXFlushTime()nvmlDeviceGetDisplayMode()nvmlDeviceGetDisplayActive()nvmlDeviceGetPersistenceMode()nvmlDeviceGetPciInfoExt()nvmlDeviceGetPciInfo_v3()nvmlDeviceGetPciInfo()nvmlDeviceGetClockInfo()nvmlDeviceGetMaxClockInfo()nvmlDeviceGetApplicationsClock()nvmlDeviceGetMaxCustomerBoostClock()nvmlDeviceGetClock()nvmlDeviceGetDefaultApplicationsClock()nvmlDeviceGetSupportedMemoryClocks()nvmlDeviceGetSupportedGraphicsClocks()nvmlDeviceGetFanSpeed()nvmlDeviceGetFanSpeed_v2()nvmlDeviceGetFanSpeedRPM()nvmlDeviceGetTargetFanSpeed()nvmlDeviceGetNumFans()nvmlDeviceSetDefaultFanSpeed_v2()nvmlDeviceGetMinMaxFanSpeed()nvmlDeviceGetFanControlPolicy_v2()nvmlDeviceSetFanControlPolicy()nvmlDeviceGetTemperatureV1()nvmlDeviceGetTemperatureV()nvmlDeviceGetTemperature()nvmlDeviceGetTemperatureThreshold()nvmlDeviceSetTemperatureThreshold()nvmlDeviceGetMarginTemperature()nvmlDeviceGetPowerState()nvmlDeviceGetPerformanceState()nvmlDeviceGetPowerManagementMode()nvmlDeviceGetPowerManagementLimit()nvmlDeviceGetPowerManagementLimitConstraints()nvmlDeviceGetPowerManagementDefaultLimit()nvmlDeviceGetEnforcedPowerLimit()nvmlDeviceGetPowerUsage()nvmlDeviceGetTotalEnergyConsumption()nvmlDeviceGetGpuOperationMode()nvmlDeviceGetCurrentGpuOperationMode()nvmlDeviceGetPendingGpuOperationMode()nvmlDeviceGetMemoryInfo()nvmlDeviceGetBAR1MemoryInfo()nvmlDeviceGetComputeMode()nvmlDeviceGetCudaComputeCapability()nvmlDeviceGetEccMode()nvmlDeviceGetCurrentEccMode()nvmlDeviceGetPendingEccMode()nvmlDeviceGetDefaultEccMode()nvmlDeviceGetTotalEccErrors()nvmlDeviceGetDetailedEccErrors()nvmlDeviceGetMemoryErrorCounter()nvmlDeviceGetUtilizationRates()nvmlDeviceGetEncoderUtilization()nvmlDeviceGetDecoderUtilization()nvmlDeviceGetJpgUtilization()nvmlDeviceGetOfaUtilization()nvmlDeviceGetPcieReplayCounter()nvmlDeviceGetDriverModel_v1()nvmlDeviceGetDriverModel_v2()nvmlDeviceGetDriverModel()nvmlDeviceGetCurrentDriverModel()nvmlDeviceGetPendingDriverModel()nvmlDeviceGetVbiosVersion()nvmlDeviceGetComputeRunningProcesses_v2()nvmlDeviceGetComputeRunningProcesses_v3()nvmlDeviceGetComputeRunningProcesses()nvmlDeviceGetGraphicsRunningProcesses_v2()nvmlDeviceGetGraphicsRunningProcesses_v3()nvmlDeviceGetGraphicsRunningProcesses()nvmlDeviceGetMPSComputeRunningProcesses()nvmlDeviceGetMPSComputeRunningProcesses_v2()nvmlDeviceGetMPSComputeRunningProcesses_v3()nvmlDeviceGetRunningProcessDetailList()nvmlDeviceGetAutoBoostedClocksEnabled()nvmlUnitSetLedState()nvmlDeviceSetPersistenceMode()nvmlDeviceSetComputeMode()nvmlDeviceSetEccMode()nvmlDeviceClearEccErrorCounts()nvmlDeviceSetDriverModel()nvmlDeviceSetAutoBoostedClocksEnabled()nvmlDeviceSetDefaultAutoBoostedClocksEnabled()nvmlDeviceSetGpuLockedClocks()nvmlDeviceResetGpuLockedClocks()nvmlDeviceSetMemoryLockedClocks()nvmlDeviceResetMemoryLockedClocks()nvmlDeviceGetClkMonStatus()nvmlDeviceSetApplicationsClocks()nvmlDeviceResetApplicationsClocks()nvmlDeviceSetPowerManagementLimit()nvmlDeviceSetGpuOperationMode()nvmlEventSetCreate()nvmlDeviceRegisterEvents()nvmlDeviceGetSupportedEventTypes()nvmlEventSetWait_v2()nvmlEventSetWait()nvmlEventSetFree()nvmlDeviceOnSameBoard()nvmlDeviceGetCurrPcieLinkGeneration()nvmlDeviceGetMaxPcieLinkGeneration()nvmlDeviceGetCurrPcieLinkWidth()nvmlDeviceGetMaxPcieLinkWidth()nvmlDeviceGetGpuMaxPcieLinkGeneration()nvmlDeviceGetSupportedClocksThrottleReasons()nvmlDeviceGetSupportedClocksEventReasons()nvmlDeviceGetCurrentClocksThrottleReasons()nvmlDeviceGetCurrentClocksEventReasons()nvmlDeviceGetIndex()nvmlDeviceGetAccountingMode()nvmlDeviceSetAccountingMode()nvmlDeviceClearAccountingPids()nvmlDeviceGetAccountingStats()nvmlDeviceGetAccountingStats_v2()nvmlDeviceGetAccountingPids()nvmlDeviceGetAccountingBufferSize()nvmlDeviceGetRetiredPages()nvmlDeviceGetRetiredPages_v2()nvmlDeviceGetRetiredPagesPendingStatus()nvmlDeviceGetAPIRestriction()nvmlDeviceSetAPIRestriction()nvmlDeviceGetBridgeChipInfo()nvmlDeviceGetSamples()nvmlDeviceGetViolationStatus()nvmlDeviceGetPcieThroughput()nvmlSystemGetTopologyGpuSet()nvmlDeviceGetTopologyNearestGpus()nvmlDeviceGetTopologyCommonAncestor()nvmlDeviceGetNvLinkUtilizationCounter()nvmlDeviceFreezeNvLinkUtilizationCounter()nvmlDeviceResetNvLinkUtilizationCounter()nvmlDeviceSetNvLinkUtilizationControl()nvmlDeviceGetNvLinkUtilizationControl()nvmlDeviceGetNvLinkCapability()nvmlDeviceGetNvLinkErrorCounter()nvmlDeviceResetNvLinkErrorCounters()nvmlDeviceGetNvLinkRemotePciInfo()nvmlDeviceGetNvLinkRemoteDeviceType()nvmlDeviceGetNvLinkState()nvmlDeviceGetNvLinkVersion()nvmlDeviceModifyDrainState()nvmlDeviceQueryDrainState()nvmlDeviceRemoveGpu()nvmlDeviceDiscoverGpus()nvmlDeviceGetFieldValues()nvmlDeviceClearFieldValues()nvmlDeviceGetVirtualizationMode()nvmlDeviceSetVirtualizationMode()nvmlDeviceGetVgpuHeterogeneousMode()nvmlDeviceSetVgpuHeterogeneousMode()nvmlVgpuInstanceGetPlacementId()nvmlDeviceGetVgpuTypeSupportedPlacements()nvmlDeviceGetVgpuTypeCreatablePlacements()nvmlGetVgpuDriverCapabilities()nvmlDeviceGetVgpuCapabilities()nvmlDeviceSetVgpuCapabilities()nvmlDeviceVgpuForceGspUnload()nvmlDeviceGetSupportedVgpus()nvmlDeviceGetCreatableVgpus()nvmlVgpuTypeGetGpuInstanceProfileId()nvmlVgpuTypeGetClass()nvmlVgpuTypeGetName()nvmlVgpuTypeGetDeviceID()nvmlVgpuTypeGetFramebufferSize()nvmlVgpuTypeGetNumDisplayHeads()nvmlVgpuTypeGetResolution()nvmlVgpuTypeGetLicense()nvmlVgpuTypeGetFrameRateLimit()nvmlVgpuTypeGetGspHeapSize()nvmlVgpuTypeGetFbReservation()nvmlVgpuInstanceGetRuntimeStateSize()nvmlVgpuTypeGetMaxInstances()nvmlVgpuTypeGetMaxInstancesPerVm()nvmlVgpuTypeGetBAR1Info()nvmlDeviceGetActiveVgpus()nvmlVgpuInstanceGetVmID()nvmlVgpuInstanceGetUUID()nvmlVgpuInstanceGetMdevUUID()nvmlVgpuInstanceGetVmDriverVersion()nvmlVgpuInstanceGetLicenseStatus()nvmlVgpuInstanceGetLicenseInfo_v2()nvmlVgpuInstanceGetLicenseInfo()nvmlVgpuInstanceGetFrameRateLimit()nvmlVgpuInstanceGetEccMode()nvmlVgpuInstanceGetType()nvmlVgpuInstanceGetEncoderCapacity()nvmlVgpuInstanceSetEncoderCapacity()nvmlVgpuInstanceGetFbUsage()nvmlVgpuTypeGetCapabilities()nvmlVgpuInstanceGetGpuInstanceId()nvmlVgpuInstanceGetGpuPciId()nvmlDeviceGetVgpuUtilization()nvmlDeviceGetVgpuInstancesUtilizationInfo()nvmlDeviceGetP2PStatus()nvmlDeviceGetGridLicensableFeatures_v4()nvmlDeviceGetGridLicensableFeatures()nvmlDeviceGetGspFirmwareVersion()nvmlDeviceGetGspFirmwareMode()nvmlDeviceGetEncoderCapacity()nvmlDeviceGetVgpuProcessUtilization()nvmlDeviceGetVgpuProcessesUtilizationInfo()nvmlDeviceGetEncoderStats()nvmlDeviceGetEncoderSessions()nvmlDeviceGetFBCStats()nvmlDeviceGetFBCSessions()nvmlVgpuInstanceGetEncoderStats()nvmlVgpuInstanceGetEncoderSessions()nvmlVgpuInstanceGetFBCStats()nvmlVgpuInstanceGetFBCSessions()nvmlDeviceGetProcessUtilization()nvmlDeviceGetProcessesUtilizationInfo()nvmlVgpuInstanceGetMetadata()nvmlDeviceGetVgpuMetadata()nvmlGetVgpuCompatibility()nvmlDeviceGetPgpuMetadataString()nvmlDeviceGetVgpuSchedulerLog()nvmlDeviceGetVgpuSchedulerState()nvmlDeviceGetVgpuSchedulerCapabilities()nvmlDeviceSetVgpuSchedulerState()nvmlSetVgpuVersion()nvmlGetVgpuVersion()nvmlVgpuInstanceGetAccountingMode()nvmlVgpuInstanceGetAccountingPids()nvmlVgpuInstanceGetAccountingStats()nvmlVgpuInstanceClearAccountingPids()nvmlGpuInstanceGetCreatableVgpus()nvmlVgpuTypeGetMaxInstancesPerGpuInstance()nvmlGpuInstanceGetActiveVgpus()nvmlGpuInstanceSetVgpuSchedulerState()nvmlGpuInstanceGetVgpuSchedulerState()nvmlGpuInstanceGetVgpuSchedulerLog()nvmlGpuInstanceGetVgpuTypeCreatablePlacements()nvmlGpuInstanceGetVgpuHeterogeneousMode()nvmlGpuInstanceSetVgpuHeterogeneousMode()nvmlDeviceGetVgpuSchedulerState_v2()nvmlGpuInstanceGetVgpuSchedulerState_v2()nvmlDeviceGetVgpuSchedulerLog_v2()nvmlGpuInstanceGetVgpuSchedulerLog_v2()nvmlDeviceSetVgpuSchedulerState_v2()nvmlGpuInstanceSetVgpuSchedulerState_v2()nvmlGetExcludedDeviceCount()nvmlGetExcludedDeviceInfoByIndex()nvmlDeviceGetHostVgpuMode()nvmlDeviceSetMigMode()nvmlDeviceGetMigMode()nvmlDeviceGetGpuInstanceProfileInfo()nvmlDeviceGetGpuInstanceProfileInfoById()nvmlDeviceGetGpuInstanceProfileInfoV()nvmlDeviceGetGpuInstanceProfileInfoByIdV()nvmlDeviceGetGpuInstanceRemainingCapacity()nvmlDeviceGetGpuInstancePossiblePlacements()nvmlDeviceCreateGpuInstance()nvmlDeviceCreateGpuInstanceWithPlacement()nvmlGpuInstanceDestroy()nvmlDeviceGetGpuInstances()nvmlDeviceGetGpuInstanceById()nvmlGpuInstanceGetInfo()nvmlGpuInstanceGetComputeInstanceProfileInfo()nvmlGpuInstanceGetComputeInstanceProfileInfoV()nvmlGpuInstanceGetComputeInstanceRemainingCapacity()nvmlGpuInstanceGetComputeInstancePossiblePlacements()nvmlGpuInstanceCreateComputeInstance()nvmlGpuInstanceCreateComputeInstanceWithPlacement()nvmlComputeInstanceDestroy()nvmlGpuInstanceGetComputeInstances()nvmlGpuInstanceGetComputeInstanceById()nvmlComputeInstanceGetInfo_v2()nvmlComputeInstanceGetInfo()nvmlDeviceIsMigDeviceHandle()nvmlDeviceGetGpuInstanceId()nvmlDeviceGetComputeInstanceId()nvmlDeviceGetMaxMigDeviceCount()nvmlDeviceGetMigDeviceHandleByIndex()nvmlDeviceGetDeviceHandleFromMigDeviceHandle()nvmlDeviceGetAttributes_v2()nvmlDeviceGetAttributes()nvmlDeviceGetRemappedRows()nvmlDeviceGetRowRemapperHistogram()nvmlDeviceGetArchitecture()nvmlDeviceGetBusType()nvmlDeviceGetIrqNum()nvmlDeviceGetNumGpuCores()nvmlDeviceGetPowerSource()nvmlDeviceGetMemoryBusWidth()nvmlDeviceGetPcieLinkMaxSpeed()nvmlDeviceGetAdaptiveClockInfoStatus()nvmlDeviceGetPcieSpeed()nvmlDeviceGetDynamicPstatesInfo()nvmlDeviceSetFanSpeed_v2()nvmlDeviceGetThermalSettings()nvmlDeviceGetMinMaxClockOfPState()nvmlDeviceGetPowerMizerMode_v1()nvmlDeviceSetPowerMizerMode_v1()nvmlDeviceGetClockOffsets()nvmlDeviceSetClockOffsets()nvmlDeviceGetSupportedPerformanceStates()nvmlDeviceGetGpcClkVfOffset()nvmlDeviceSetGpcClkVfOffset()nvmlDeviceGetGpcClkMinMaxVfOffset()nvmlDeviceGetMemClkVfOffset()nvmlDeviceSetMemClkVfOffset()nvmlDeviceGetMemClkMinMaxVfOffset()nvmlSystemSetConfComputeGpusReadyState()nvmlSystemGetConfComputeGpusReadyState()nvmlSystemGetConfComputeCapabilities()nvmlSystemGetConfComputeState()nvmlSystemGetConfComputeSettings()nvmlDeviceSetConfComputeUnprotectedMemSize()nvmlDeviceGetConfComputeMemSizeInfo()nvmlDeviceGetConfComputeProtectedMemoryUsage()nvmlDeviceGetConfComputeGpuCertificate()nvmlDeviceGetConfComputeGpuAttestationReport()nvmlSystemSetConfComputeKeyRotationThresholdInfo()nvmlSystemGetConfComputeKeyRotationThresholdInfo()nvmlGpmMetricsGet()nvmlGpmSampleFree()nvmlGpmSampleAlloc()nvmlGpmSampleGet()nvmlGpmMigSampleGet()nvmlGpmQueryDeviceSupport()nvmlGpmSetStreamingEnabled()nvmlGpmQueryIfStreamingEnabled()nvmlDeviceSetNvLinkDeviceLowPowerThreshold()nvmlDeviceGetGpuFabricInfo()nvmlDeviceGetGpuFabricInfoV()nvmlSystemSetNvlinkBwMode()nvmlSystemGetNvlinkBwMode()nvmlDeviceSetPowerManagementLimit_v2()nvmlDeviceGetSramEccErrorStatus()nvmlDeviceGetCapabilities()nvmlDeviceGetPlatformInfo()nvmlDeviceWorkloadPowerProfileGetProfilesInfo()nvmlDeviceWorkloadPowerProfileGetCurrentProfiles()nvmlDeviceWorkloadPowerProfileSetRequestedProfiles()nvmlDeviceWorkloadPowerProfileClearRequestedProfiles()nvmlDeviceWorkloadPowerProfileUpdateProfiles_v1()nvmlDeviceGetNvlinkSupportedBwModes()nvmlDeviceGetNvlinkBwMode()nvmlDeviceSetNvlinkBwMode()nvmlDeviceGetDramEncryptionMode()nvmlDeviceGetCurrentDramEncryptionMode()nvmlDeviceGetPendingDramEncryptionMode()nvmlDeviceSetDramEncryptionMode()nvmlDevicePowerSmoothingActivatePresetProfile()nvmlDevicePowerSmoothingUpdatePresetProfileParam()nvmlDevicePowerSmoothingSetState()nvmlDeviceGetSramUniqueUncorrectedEccErrorCounts()nvmlDeviceGetPdi()nvmlDeviceGetNvLinkInfo()nvmlDeviceGetRepairStatus()nvmlDeviceSetHostname_v1()nvmlDeviceGetHostname_v1()nvmlDeviceGetUnrepairableMemoryFlag_v1()nvmlDeviceSetRusdSettings_v1()nvmlDeviceGetRemappedRows_v2()
- Constants
- nvitop.libcuda module
CUDA_SUCCESSCUDA_ERROR_INVALID_VALUECUDA_ERROR_OUT_OF_MEMORYCUDA_ERROR_NOT_INITIALIZEDCUDA_ERROR_DEINITIALIZEDCUDA_ERROR_PROFILER_DISABLEDCUDA_ERROR_STUB_LIBRARYCUDA_ERROR_DEVICE_UNAVAILABLECUDA_ERROR_NO_DEVICECUDA_ERROR_INVALID_DEVICECUDA_ERROR_DEVICE_NOT_LICENSEDCUDA_ERROR_INVALID_IMAGECUDA_ERROR_INVALID_CONTEXTCUDA_ERROR_MAP_FAILEDCUDA_ERROR_UNMAP_FAILEDCUDA_ERROR_ARRAY_IS_MAPPEDCUDA_ERROR_ALREADY_MAPPEDCUDA_ERROR_NO_BINARY_FOR_GPUCUDA_ERROR_ALREADY_ACQUIREDCUDA_ERROR_NOT_MAPPEDCUDA_ERROR_NOT_MAPPED_AS_ARRAYCUDA_ERROR_NOT_MAPPED_AS_POINTERCUDA_ERROR_ECC_UNCORRECTABLECUDA_ERROR_UNSUPPORTED_LIMITCUDA_ERROR_CONTEXT_ALREADY_IN_USECUDA_ERROR_PEER_ACCESS_UNSUPPORTEDCUDA_ERROR_INVALID_PTXCUDA_ERROR_INVALID_GRAPHICS_CONTEXTCUDA_ERROR_NVLINK_UNCORRECTABLECUDA_ERROR_JIT_COMPILER_NOT_FOUNDCUDA_ERROR_UNSUPPORTED_PTX_VERSIONCUDA_ERROR_JIT_COMPILATION_DISABLEDCUDA_ERROR_UNSUPPORTED_EXEC_AFFINITYCUDA_ERROR_INVALID_SOURCECUDA_ERROR_FILE_NOT_FOUNDCUDA_ERROR_SHARED_OBJECT_SYMBOL_NOT_FOUNDCUDA_ERROR_SHARED_OBJECT_INIT_FAILEDCUDA_ERROR_OPERATING_SYSTEMCUDA_ERROR_INVALID_HANDLECUDA_ERROR_ILLEGAL_STATECUDA_ERROR_NOT_FOUNDCUDA_ERROR_NOT_READYCUDA_ERROR_ILLEGAL_ADDRESSCUDA_ERROR_LAUNCH_OUT_OF_RESOURCESCUDA_ERROR_LAUNCH_TIMEOUTCUDA_ERROR_LAUNCH_INCOMPATIBLE_TEXTURINGCUDA_ERROR_PEER_ACCESS_ALREADY_ENABLEDCUDA_ERROR_PEER_ACCESS_NOT_ENABLEDCUDA_ERROR_PRIMARY_CONTEXT_ACTIVECUDA_ERROR_CONTEXT_IS_DESTROYEDCUDA_ERROR_ASSERTCUDA_ERROR_TOO_MANY_PEERSCUDA_ERROR_HOST_MEMORY_ALREADY_REGISTEREDCUDA_ERROR_HOST_MEMORY_NOT_REGISTEREDCUDA_ERROR_HARDWARE_STACK_ERRORCUDA_ERROR_ILLEGAL_INSTRUCTIONCUDA_ERROR_MISALIGNED_ADDRESSCUDA_ERROR_INVALID_ADDRESS_SPACECUDA_ERROR_INVALID_PCCUDA_ERROR_LAUNCH_FAILEDCUDA_ERROR_COOPERATIVE_LAUNCH_TOO_LARGECUDA_ERROR_NOT_PERMITTEDCUDA_ERROR_NOT_SUPPORTEDCUDA_ERROR_SYSTEM_NOT_READYCUDA_ERROR_SYSTEM_DRIVER_MISMATCHCUDA_ERROR_COMPAT_NOT_SUPPORTED_ON_DEVICECUDA_ERROR_MPS_CONNECTION_FAILEDCUDA_ERROR_MPS_RPC_FAILURECUDA_ERROR_MPS_SERVER_NOT_READYCUDA_ERROR_MPS_MAX_CLIENTS_REACHEDCUDA_ERROR_MPS_MAX_CONNECTIONS_REACHEDCUDA_ERROR_STREAM_CAPTURE_UNSUPPORTEDCUDA_ERROR_STREAM_CAPTURE_INVALIDATEDCUDA_ERROR_STREAM_CAPTURE_MERGECUDA_ERROR_STREAM_CAPTURE_UNMATCHEDCUDA_ERROR_STREAM_CAPTURE_UNJOINEDCUDA_ERROR_STREAM_CAPTURE_ISOLATIONCUDA_ERROR_STREAM_CAPTURE_IMPLICITCUDA_ERROR_CAPTURED_EVENTCUDA_ERROR_STREAM_CAPTURE_WRONG_THREADCUDA_ERROR_TIMEOUTCUDA_ERROR_GRAPH_EXEC_UPDATE_FAILURECUDA_ERROR_EXTERNAL_DEVICECUDA_ERROR_UNKNOWN
- nvitop.libcudart module
cudaSuccesscudaErrorInvalidValuecudaErrorMemoryAllocationcudaErrorInitializationErrorcudaErrorCudartUnloadingcudaErrorProfilerDisabledcudaErrorInvalidConfigurationcudaErrorInvalidPitchValuecudaErrorInvalidSymbolcudaErrorInvalidTexturecudaErrorInvalidTextureBindingcudaErrorInvalidChannelDescriptorcudaErrorInvalidMemcpyDirectioncudaErrorInvalidFilterSettingcudaErrorInvalidNormSettingcudaErrorStubLibrarycudaErrorInsufficientDrivercudaErrorCallRequiresNewerDrivercudaErrorInvalidSurfacecudaErrorDuplicateVariableNamecudaErrorDuplicateTextureNamecudaErrorDuplicateSurfaceNamecudaErrorDevicesUnavailablecudaErrorIncompatibleDriverContextcudaErrorMissingConfigurationcudaErrorLaunchMaxDepthExceededcudaErrorLaunchFileScopedTexcudaErrorLaunchFileScopedSurfcudaErrorSyncDepthExceededcudaErrorLaunchPendingCountExceededcudaErrorInvalidDeviceFunctioncudaErrorNoDevicecudaErrorInvalidDevicecudaErrorDeviceNotLicensedcudaErrorSoftwareValidityNotEstablishedcudaErrorStartupFailurecudaErrorInvalidKernelImagecudaErrorDeviceUninitializedcudaErrorMapBufferObjectFailedcudaErrorUnmapBufferObjectFailedcudaErrorArrayIsMappedcudaErrorAlreadyMappedcudaErrorNoKernelImageForDevicecudaErrorAlreadyAcquiredcudaErrorNotMappedcudaErrorNotMappedAsArraycudaErrorNotMappedAsPointercudaErrorECCUncorrectablecudaErrorUnsupportedLimitcudaErrorDeviceAlreadyInUsecudaErrorPeerAccessUnsupportedcudaErrorInvalidPtxcudaErrorInvalidGraphicsContextcudaErrorNvlinkUncorrectablecudaErrorJitCompilerNotFoundcudaErrorUnsupportedPtxVersioncudaErrorJitCompilationDisabledcudaErrorUnsupportedExecAffinitycudaErrorInvalidSourcecudaErrorFileNotFoundcudaErrorSharedObjectSymbolNotFoundcudaErrorSharedObjectInitFailedcudaErrorOperatingSystemcudaErrorInvalidResourceHandlecudaErrorIllegalStatecudaErrorSymbolNotFoundcudaErrorNotReadycudaErrorIllegalAddresscudaErrorLaunchOutOfResourcescudaErrorLaunchTimeoutcudaErrorLaunchIncompatibleTexturingcudaErrorPeerAccessAlreadyEnabledcudaErrorPeerAccessNotEnabledcudaErrorSetOnActiveProcesscudaErrorContextIsDestroyedcudaErrorAssertcudaErrorTooManyPeerscudaErrorHostMemoryAlreadyRegisteredcudaErrorHostMemoryNotRegisteredcudaErrorHardwareStackErrorcudaErrorIllegalInstructioncudaErrorMisalignedAddresscudaErrorInvalidAddressSpacecudaErrorInvalidPccudaErrorLaunchFailurecudaErrorCooperativeLaunchTooLargecudaErrorNotPermittedcudaErrorNotSupportedcudaErrorSystemNotReadycudaErrorSystemDriverMismatchcudaErrorCompatNotSupportedOnDevicecudaErrorMpsConnectionFailedcudaErrorMpsRpcFailurecudaErrorMpsServerNotReadycudaErrorMpsMaxClientsReachedcudaErrorMpsMaxConnectionsReachedcudaErrorMpsClientTerminatedcudaErrorCdpNotSupportedcudaErrorCdpVersionMismatchcudaErrorStreamCaptureUnsupportedcudaErrorStreamCaptureInvalidatedcudaErrorStreamCaptureMergecudaErrorStreamCaptureUnmatchedcudaErrorStreamCaptureUnjoinedcudaErrorStreamCaptureIsolationcudaErrorStreamCaptureImplicitcudaErrorCapturedEventcudaErrorStreamCaptureWrongThreadcudaErrorTimeoutcudaErrorGraphExecUpdateFailurecudaErrorExternalDevicecudaErrorInvalidClusterSizecudaErrorUnknown
- nvitop.caching module
- nvitop.utils module
- nvitop.select module
Module Contents
An interactive NVIDIA-GPU process viewer and beyond, the one-stop solution for GPU process management.
- nvitop.version.PYNVML_VERSION_CANDIDATES = ('11.450.51', '11.450.129', '11.460.79', '11.470.66', '11.495.46', '11.510.69', '11.515.48', '11.515.75', '11.525.84', '11.525.112', '11.525.131', '11.525.150', '12.535.77', '12.535.108', '12.535.133', '12.535.161', '12.550.52', '12.550.89', '12.555.43', '12.560.30', '12.570.86', '12.570.172', '12.575.51', '13.580.65', '13.580.82', '13.580.126', '13.590.44', '13.590.48', '13.595.45', '13.610.43')
The list of supported
nvidia-ml-pyversions. See also: nvidia-ml-py’s Release History.To install
nvitopwith a specific version ofnvidia-ml-py, use:pip3 install nvidia-ml-py==xx.yyy.zz nvitop
or
pip3 install 'nvitop[cudaXX]'
Note
The package
nvidia-ml-pyis not backward compatible over releases. This may cause problems such as “Function Not Found” errors with old versions of NVIDIA drivers (e.g. the NVIDIA R430 driver on Ubuntu 16.04 LTS). The ideal solution is to let the user install the best-fit version ofnvidia-ml-py. See also: nvidia-ml-py’s Release History.nvidia-ml-py==11.450.51is the last version supports the NVIDIA R430 driver (CUDA 10.x). Sincenvidia-ml-py>=11.450.129, the definition of structnvmlProcessInfo_thas introduced two new fieldsgpuInstanceIdandcomputeInstanceId(GI ID and CI ID in newernvidia-smi) which are incompatible with some old NVIDIA drivers.nvitopmay not display the processes correctly due to this incompatibility.
- final class nvitop.NaType[source]
Bases:
strA singleton (
str: 'N/A') class represents a not applicable value.The
NAinstance behaves like astrinstance ('N/A') when doing string manipulation (e.g. concatenation). For arithmetic operations, for exampleNA / 1024 / 1024, it acts like themath.nan.Examples
>>> NA 'N/A'
>>> 'memory usage: {}'.format(NA) # NA is an instance of `str` 'memory usage: N/A' >>> NA.lower() # NA is an instance of `str` 'n/a' >>> NA.ljust(5) # NA is an instance of `str` 'N/A ' >>> NA + ' str' # string contamination if the operand is a string 'N/A str'
>>> float(NA) # explicit conversion to float (`math.nan`) nan >>> NA + 1 # auto-casting to float if the operand is a number nan >>> NA * 1024 # auto-casting to float if the operand is a number nan >>> NA / (1024 * 1024) # auto-casting to float if the operand is a number nan
- __float__() float[source]
Convert
NAtofloatand returnmath.nan.>>> float(NA) nan >>> float(NA) is math.nan True
- __add__(other: object) str | float[source]
Return
math.nanif the operand is a number or uses string concatenation if the operand is a string (NA + other).A special case is when the operand is
nvitop.NAitself, the result ismath.naninstead of'N/AN/A'.>>> NA + ' str' 'N/A str' >>> NA + NA nan >>> NA + 1 nan >>> NA + 1.0 nan
- __radd__(other: object) str | float[source]
Return
math.nanif the operand is a number or uses string concatenation if the operand is a string (other + NA).>>> 'str' + NA 'strN/A' >>> 1 + NA nan >>> 1.0 + NA nan
- __sub__(other: object) float[source]
Return
math.nanif the operand is a number (NA - other).>>> NA - 'str' Traceback (most recent call last): ... TypeError: unsupported operand type(s) for -: 'NaType' and 'str' >>> NA - NA nan >>> NA + 1 nan >>> NA + 1.0 nan
- __rsub__(other: object) float[source]
Return
math.nanif the operand is a number (other - NA).>>> 'str' - NA Traceback (most recent call last): ... TypeError: unsupported operand type(s) for -: 'str' and 'NaType' >>> 1 - NA nan >>> 1.0 - NA nan
- __mul__(other: object) float[source]
Return
math.nanif the operand is a number (NA * other).A special case is when the operand is
nvitop.NAitself, the result is alsomath.nan.>>> NA * 1024 nan >>> NA * 1024.0 nan >>> NA * NA nan
- __rmul__(other: object) float[source]
Return
math.nanif the operand is a number (other * NA).>>> 1024 * NA nan >>> 1024.0 * NA nan
- __truediv__(other: object) float[source]
Return
math.nanif the operand is a number (NA / other).>>> NA / 1024 nan >>> NA / 1024.0 nan >>> NA / 0 Traceback (most recent call last): ... ZeroDivisionError: ... >>> NA / 0.0 Traceback (most recent call last): ... ZeroDivisionError: ... >>> NA / NA nan
- __rtruediv__(other: object) float[source]
Return
math.nanif the operand is a number (other / NA).>>> 1024 / NA nan >>> 1024.0 / NA nan
- __floordiv__(other: object) float[source]
Return
math.nanif the operand is a number (NA // other).>>> NA // 1024 nan >>> NA // 1024.0 nan >>> NA / 0 Traceback (most recent call last): ... ZeroDivisionError: ... >>> NA / 0.0 Traceback (most recent call last): ... ZeroDivisionError: ... >>> NA // NA nan
- __rfloordiv__(other: object) float[source]
Return
math.nanif the operand is a number (other // NA).>>> 1024 // NA nan >>> 1024.0 // NA nan
- __mod__(other: object) float[source]
Return
math.nanif the operand is a number (NA % other).>>> NA % 1024 nan >>> NA % 1024.0 nan >>> NA % 0 Traceback (most recent call last): ... ZeroDivisionError: ... >>> NA % 0.0 Traceback (most recent call last): ... ZeroDivisionError: ...
- __rmod__(other: object) float[source]
Return
math.nanif the operand is a number (other % NA).>>> 1024 % NA nan >>> 1024.0 % NA nan
- __divmod__(other: object) tuple[float, float][source]
The pair
(NA // other, NA % other)(divmod(NA, other)).>>> divmod(NA, 1024) (nan, nan) >>> divmod(NA, 1024.0) (nan, nan) >>> divmod(NA, 0) Traceback (most recent call last): ... ZeroDivisionError: ... >>> divmod(NA, 0.0) Traceback (most recent call last): ... ZeroDivisionError: ...
- __rdivmod__(other: object) tuple[float, float][source]
The pair
(other // NA, other % NA)(divmod(other, NA)).>>> divmod(1024, NA) (nan, nan) >>> divmod(1024.0, NA) (nan, nan)
- __round__(ndigits: int | None = None) int | float[source]
Round
nvitop.NAtondigitsdecimal places, defaulting toNone.If
ndigitsis omitted orNone, returns0, otherwise returnsmath.nan.>>> round(NA) 0 >>> round(NA, 0) nan >>> round(NA, 1) nan
- __lt__(x: object) bool[source]
The
nvitop.NAis always greater than any number, or uses the dictionary order for string.
- __le__(x: object) bool[source]
The
nvitop.NAis always greater than any number, or uses the dictionary order for string.
- __gt__(x: object) bool[source]
The
nvitop.NAis always greater than any number, or uses the dictionary order for string.
- nvitop.NA = 'N/A'
A singleton (
str: 'N/A') class represents a not applicable value.The
NAinstance behaves like astrinstance ('N/A') when doing string manipulation (e.g. concatenation). For arithmetic operations, for exampleNA / 1024 / 1024, it acts like themath.nan.Examples
>>> NA 'N/A'
>>> 'memory usage: {}'.format(NA) # NA is an instance of `str` 'memory usage: N/A' >>> NA.lower() # NA is an instance of `str` 'n/a' >>> NA.ljust(5) # NA is an instance of `str` 'N/A ' >>> NA + ' str' # string contamination if the operand is a string 'N/A str'
>>> float(NA) # explicit conversion to float (`math.nan`) nan >>> NA + 1 # auto-casting to float if the operand is a number nan >>> NA * 1024 # auto-casting to float if the operand is a number nan >>> NA / (1024 * 1024) # auto-casting to float if the operand is a number nan
- nvitop.NotApplicable = 'N/A'
A singleton (
str: 'N/A') class represents a not applicable value.The
NAinstance behaves like astrinstance ('N/A') when doing string manipulation (e.g. concatenation). For arithmetic operations, for exampleNA / 1024 / 1024, it acts like themath.nan.Examples
>>> NA 'N/A'
>>> 'memory usage: {}'.format(NA) # NA is an instance of `str` 'memory usage: N/A' >>> NA.lower() # NA is an instance of `str` 'n/a' >>> NA.ljust(5) # NA is an instance of `str` 'N/A ' >>> NA + ' str' # string contamination if the operand is a string 'N/A str'
>>> float(NA) # explicit conversion to float (`math.nan`) nan >>> NA + 1 # auto-casting to float if the operand is a number nan >>> NA * 1024 # auto-casting to float if the operand is a number nan >>> NA / (1024 * 1024) # auto-casting to float if the operand is a number nan
An interactive NVIDIA-GPU process viewer and beyond, the one-stop solution for GPU process management.
- exception nvitop.NVMLError(value)[source]
Bases:
ExceptionBase exception class for NVML query errors.
- static __new__(typ, value)[source]
Map value to a proper subclass of
NVMLError.
- nvitop.nvmlCheckReturn(retval: Any, types: type | tuple[type, ...] | None = None, /) bool[source]
Check whether the return value is not
nvitop.NAand is one of the given types.
- class nvitop.Device(index: int | tuple[int, int] | str | None = None, *, uuid: str | None = None, bus_id: str | None = None)[source]
Bases:
objectLive class of the GPU devices, different from the device snapshots.
Device.__new__()returns different types depending on the given arguments.- (index: int) -> PhysicalDevice - (index: (int, int)) -> MigDevice - (uuid: str) -> Union[PhysicalDevice, MigDevice] # depending on the UUID value - (bus_id: str) -> PhysicalDevice
Examples
>>> Device.driver_version() # version of the installed NVIDIA display driver '470.129.06'
>>> Device.count() # number of NVIDIA GPUs in the system 10
>>> Device.all() # all physical devices in the system [ PhysicalDevice(index=0, ...), PhysicalDevice(index=1, ...), ... ]
>>> nvidia0 = Device(index=0) # -> PhysicalDevice >>> mig10 = Device(index=(1, 0)) # -> MigDevice >>> nvidia2 = Device(uuid='GPU-xxxxxx') # -> PhysicalDevice >>> mig30 = Device(uuid='MIG-xxxxxx') # -> MigDevice
>>> nvidia0.memory_free() # total free memory in bytes 11550654464 >>> nvidia0.memory_free_human() # total free memory in human-readable format '11016MiB'
>>> nvidia2.as_snapshot() # takes a one-time snapshot of the device PhysicalDeviceSnapshot( real=PhysicalDevice(index=2, ...), ... )
- Raises:
libnvml.NVMLError_LibraryNotFound – If cannot find the NVML library, usually the NVIDIA driver is not installed.
libnvml.NVMLError_DriverNotLoaded – If NVIDIA driver is not loaded.
libnvml.NVMLError_LibRmVersionMismatch – If RM detects a driver/library version mismatch, usually after an upgrade for NVIDIA driver without reloading the kernel module.
libnvml.NVMLError_NotFound – If the device is not found for the given NVML identifier.
libnvml.NVMLError_InvalidArgument – If the device index is out of range.
TypeError – If the number of non-None arguments is not exactly 1.
TypeError – If the given index is a tuple but does not consist of two integers.
- UUID_PATTERN: ClassVar[re.Pattern] = re.compile('^ # full match\n (?:(?P<MigMode>MIG)-)? # prefix for MIG UUID\n (?:(?P<GpuUuid>GPU)-)? # prefix for GPU UUID\n (?, re.VERBOSE)
- GPU_PROCESS_CLASS
alias of
GpuProcess
- cuda
alias of
CudaDevice
- classmethod is_available() bool[source]
Test whether there are any devices and the NVML library is successfully loaded.
- static driver_version() str | NaType[source]
The version of the installed NVIDIA display driver. This is an alphanumeric string.
Command line equivalent:
nvidia-smi --id=0 --format=csv,noheader,nounits --query-gpu=driver_version
- Raises:
libnvml.NVMLError_LibraryNotFound – If cannot find the NVML library, usually the NVIDIA driver is not installed.
libnvml.NVMLError_DriverNotLoaded – If NVIDIA driver is not loaded.
libnvml.NVMLError_LibRmVersionMismatch – If RM detects a driver/library version mismatch, usually after an upgrade for NVIDIA driver without reloading the kernel module.
- static cuda_driver_version() str | NaType[source]
The maximum CUDA version supported by the NVIDIA display driver. This is an alphanumeric string.
This can be different from the version of the CUDA Runtime. See also
cuda_runtime_version().- Returns: Union[str, NaType]
The maximum CUDA version supported by the NVIDIA display driver.
- Raises:
libnvml.NVMLError_LibraryNotFound – If cannot find the NVML library, usually the NVIDIA driver is not installed.
libnvml.NVMLError_DriverNotLoaded – If NVIDIA driver is not loaded.
libnvml.NVMLError_LibRmVersionMismatch – If RM detects a driver/library version mismatch, usually after an upgrade for NVIDIA driver without reloading the kernel module.
- static max_cuda_version() str | NaType
The maximum CUDA version supported by the NVIDIA display driver. This is an alphanumeric string.
This can be different from the version of the CUDA Runtime. See also
cuda_runtime_version().- Returns: Union[str, NaType]
The maximum CUDA version supported by the NVIDIA display driver.
- Raises:
libnvml.NVMLError_LibraryNotFound – If cannot find the NVML library, usually the NVIDIA driver is not installed.
libnvml.NVMLError_DriverNotLoaded – If NVIDIA driver is not loaded.
libnvml.NVMLError_LibRmVersionMismatch – If RM detects a driver/library version mismatch, usually after an upgrade for NVIDIA driver without reloading the kernel module.
- static cuda_runtime_version() str | NaType[source]
The CUDA Runtime version. This is an alphanumeric string.
This can be different from the CUDA driver version. See also
cuda_driver_version().- Returns: Union[str, NaType]
The CUDA Runtime version, or
nvitop.NAwhen no CUDA Runtime is available or no CUDA-capable devices are present.
- static cudart_version() str | NaType
The CUDA Runtime version. This is an alphanumeric string.
This can be different from the CUDA driver version. See also
cuda_driver_version().- Returns: Union[str, NaType]
The CUDA Runtime version, or
nvitop.NAwhen no CUDA Runtime is available or no CUDA-capable devices are present.
- classmethod count() int[source]
The number of NVIDIA GPUs in the system.
Command line equivalent:
nvidia-smi --id=0 --format=csv,noheader,nounits --query-gpu=count
- Raises:
libnvml.NVMLError_LibraryNotFound – If cannot find the NVML library, usually the NVIDIA driver is not installed.
libnvml.NVMLError_DriverNotLoaded – If NVIDIA driver is not loaded.
libnvml.NVMLError_LibRmVersionMismatch – If RM detects a driver/library version mismatch, usually after an upgrade for NVIDIA driver without reloading the kernel module.
- classmethod all() list[PhysicalDevice][source]
Return a list of all physical devices in the system.
- classmethod from_indices(indices: int | Iterable[int | tuple[int, int]] | None = None) list[Self][source]
Return a list of devices of the given indices.
- Parameters:
indices (Iterable[Union[int, Tuple[int, int]]]) – Indices of the devices. For each index, get
PhysicalDevicefor single int andMigDevicefor tuple (int, int). That is: - (int) -> PhysicalDevice - ((int, int)) -> MigDevice
- Returns: List[Union[PhysicalDevice, MigDevice]]
A list of
PhysicalDeviceand/orMigDeviceinstances of the given indices.
- Raises:
libnvml.NVMLError_LibraryNotFound – If cannot find the NVML library, usually the NVIDIA driver is not installed.
libnvml.NVMLError_DriverNotLoaded – If NVIDIA driver is not loaded.
libnvml.NVMLError_LibRmVersionMismatch – If RM detects a driver/library version mismatch, usually after an upgrade for NVIDIA driver without reloading the kernel module.
libnvml.NVMLError_NotFound – If the device is not found for the given NVML identifier.
libnvml.NVMLError_InvalidArgument – If the device index is out of range.
- static from_cuda_visible_devices() list[CudaDevice][source]
Return a list of all CUDA visible devices.
The CUDA ordinal will be enumerate from the
CUDA_VISIBLE_DEVICESenvironment variable.Note
The result could be empty if the
CUDA_VISIBLE_DEVICESenvironment variable is invalid.- See also for CUDA Device Enumeration:
- Returns: List[CudaDevice]
A list of
CudaDeviceinstances.
- static from_cuda_indices(cuda_indices: int | Iterable[int] | None = None) list[CudaDevice][source]
Return a list of CUDA devices of the given CUDA indices.
The CUDA ordinal will be enumerate from the
CUDA_VISIBLE_DEVICESenvironment variable.- See also for CUDA Device Enumeration:
- Parameters:
cuda_indices (Iterable[int]) – The indices of the GPU in CUDA ordinal, if not given, returns all visible CUDA devices.
- Returns: List[CudaDevice]
A list of
CudaDeviceof the given CUDA indices.
- Raises:
libnvml.NVMLError_LibraryNotFound – If cannot find the NVML library, usually the NVIDIA driver is not installed.
libnvml.NVMLError_DriverNotLoaded – If NVIDIA driver is not loaded.
libnvml.NVMLError_LibRmVersionMismatch – If RM detects a driver/library version mismatch, usually after an upgrade for NVIDIA driver without reloading the kernel module.
RuntimeError – If the index is out of range for the given
CUDA_VISIBLE_DEVICESenvironment variable.
- static parse_cuda_visible_devices(cuda_visible_devices: str | None = <VALUE OMITTED>) list[int] | list[tuple[int, int]][source]
Parse the given
CUDA_VISIBLE_DEVICESvalue into a list of NVML device indices.This is an alias of
parse_cuda_visible_devices().Note
The result could be empty if the
CUDA_VISIBLE_DEVICESenvironment variable is invalid.- See also for CUDA Device Enumeration:
- Parameters:
cuda_visible_devices (Optional[str]) – The value of the
CUDA_VISIBLE_DEVICESvariable. If not given, the value from the environment will be used. If explicitly given byNone, theCUDA_VISIBLE_DEVICESenvironment variable will be unset before parsing.
- Returns: Union[List[int], List[Tuple[int, int]]]
A list of int (physical device) or a list of tuple of two integers (MIG device) for the corresponding real device indices.
- static normalize_cuda_visible_devices(cuda_visible_devices: str | None = <VALUE OMITTED>) str[source]
Parse the given
CUDA_VISIBLE_DEVICESvalue and convert it into a comma-separated string of UUIDs.This is an alias of
normalize_cuda_visible_devices().Note
The result could be empty string if the
CUDA_VISIBLE_DEVICESenvironment variable is invalid.- See also for CUDA Device Enumeration:
- Parameters:
cuda_visible_devices (Optional[str]) – The value of the
CUDA_VISIBLE_DEVICESvariable. If not given, the value from the environment will be used. If explicitly given byNone, theCUDA_VISIBLE_DEVICESenvironment variable will be unset before parsing.
- Returns: str
The comma-separated string (GPU UUIDs) of the
CUDA_VISIBLE_DEVICESenvironment variable.
- static __new__(cls, index: int | tuple[int, int] | str | None = None, *, uuid: str | None = None, bus_id: str | None = None) Self[source]
Create a new instance of Device.
The type of the result is determined by the given argument.
- (index: int) -> PhysicalDevice - (index: (int, int)) -> MigDevice - (uuid: str) -> Union[PhysicalDevice, MigDevice] # depending on the UUID value - (bus_id: str) -> PhysicalDevice
Note: This method takes exactly 1 non-None argument.
- Returns: Union[PhysicalDevice, MigDevice]
A
PhysicalDeviceinstance or aMigDeviceinstance.
- __init__(index: int | str | None = None, *, uuid: str | None = None, bus_id: str | None = None) None[source]
Initialize the instance created by
__new__().- Raises:
libnvml.NVMLError_LibraryNotFound – If cannot find the NVML library, usually the NVIDIA driver is not installed.
libnvml.NVMLError_DriverNotLoaded – If NVIDIA driver is not loaded.
libnvml.NVMLError_LibRmVersionMismatch – If RM detects a driver/library version mismatch, usually after an upgrade for NVIDIA driver without reloading the kernel module.
libnvml.NVMLError_NotFound – If the device is not found for the given NVML identifier.
libnvml.NVMLError_InvalidArgument – If the device index is out of range.
- __getattr__(name: str) Any | Callable[..., Any][source]
Get the object attribute.
If the attribute is not defined, make a method from
pynvml.nvmlDeviceGet<AttributeName>(handle). The attribute name will be converted to PascalCase string.- Raises:
AttributeError – If the attribute is not defined in
pynvml.py.
Examples
>>> device = Device(0)
>>> # Method `cuda_compute_capability` is not implemented in the class definition >>> PhysicalDevice.cuda_compute_capability AttributeError: type object 'Device' has no attribute 'cuda_compute_capability'
>>> # Dynamically create a new method from `pynvml.nvmlDeviceGetCudaComputeCapability(device.handle, *args, **kwargs)` >>> device.cuda_compute_capability <function PhysicalDevice.cuda_compute_capability at 0x7fbfddf5d9d0>
>>> device.cuda_compute_capability() (8, 6)
- __reduce__() tuple[type[Device], tuple[int | tuple[int, int]]][source]
Return state information for pickling.
- property index: int | tuple[int, int]
The NVML index of the device.
- Returns: Union[int, Tuple[int, int]]
Returns an int for physical device and tuple of two integers for MIG device.
- property nvml_index: int | tuple[int, int]
The NVML index of the device.
- Returns: Union[int, Tuple[int, int]]
Returns an int for physical device and tuple of two integers for MIG device.
- property physical_index: int
The index of the physical device.
- Returns: int
An int for the physical device index. For MIG devices, returns the index of the parent physical device.
- property handle: LP_struct_c_nvmlDevice_t | None
The NVML device handle.
- property cuda_index: int
The CUDA device index.
The value will be evaluated on the first call.
- Raises:
RuntimeError – If the current device is not visible to CUDA applications (i.e. not listed in the
CUDA_VISIBLE_DEVICESenvironment variable or the environment variable is invalid).
- name() str | NaType[source]
The official product name of the GPU. This is an alphanumeric string. For all products.
- Returns: Union[str, NaType]
The official product name, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=name
- uuid() str | NaType[source]
This value is the globally unique immutable alphanumeric identifier of the GPU.
It does not correspond to any physical label on the board.
- Returns: Union[str, NaType]
The UUID of the device, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=name
- bus_id() str | NaType[source]
PCI bus ID as “domain:bus:device.function”, in hex.
- Returns: Union[str, NaType]
The PCI bus ID of the device, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=pci.bus_id
- serial() str | NaType[source]
This number matches the serial number physically printed on each board.
It is a globally unique immutable alphanumeric value.
- Returns: Union[str, NaType]
The serial number of the device, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=serial
- memory_info() MemoryInfo[source]
Return a named tuple with memory information (in bytes) for the device.
- Returns: MemoryInfo(total, free, used, reserved)
A named tuple with memory information, the item could be
nvitop.NAwhen not applicable.
- memory_total() int | NaType[source]
Total installed GPU memory in bytes.
- Returns: Union[int, NaType]
Total installed GPU memory in bytes, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=memory.total
- memory_used() int | NaType[source]
Total memory allocated by active contexts in bytes.
- Returns: Union[int, NaType]
Total memory allocated by active contexts in bytes, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=memory.used
- memory_free() int | NaType[source]
Total free memory in bytes.
- Returns: Union[int, NaType]
Total free memory in bytes, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=memory.free
- memory_total_human() str | NaType[source]
Total installed GPU memory in human-readable format.
- Returns: Union[str, NaType]
Total installed GPU memory in human-readable format, or
nvitop.NAwhen not applicable.
- memory_used_human() str | NaType[source]
Total memory allocated by active contexts in human-readable format.
- Returns: Union[int, NaType]
Total memory allocated by active contexts in human-readable format, or
nvitop.NAwhen not applicable.
- memory_free_human() str | NaType[source]
Total free memory in human-readable format.
- Returns: Union[int, NaType]
Total free memory in human-readable format, or
nvitop.NAwhen not applicable.
- memory_percent() float | NaType[source]
The percentage of used memory over total memory (
0 <= p <= 100).- Returns: Union[float, NaType]
The percentage of used memory over total memory, or
nvitop.NAwhen not applicable.
- memory_usage() str[source]
The used memory over total memory in human-readable format.
- Returns: str
The used memory over total memory in human-readable format, or
'N/A / N/A'when not applicable.
- bar1_memory_info() MemoryInfo[source]
Return a named tuple with BAR1 memory information (in bytes) for the device.
- Returns: MemoryInfo(total, free, used)
A named tuple with BAR1 memory information, the item could be
nvitop.NAwhen not applicable.
- bar1_memory_total() int | NaType[source]
Total BAR1 memory in bytes.
- Returns: Union[int, NaType]
Total BAR1 memory in bytes, or
nvitop.NAwhen not applicable.
- bar1_memory_used() int | NaType[source]
Total used BAR1 memory in bytes.
- Returns: Union[int, NaType]
Total used BAR1 memory in bytes, or
nvitop.NAwhen not applicable.
- bar1_memory_free() int | NaType[source]
Total free BAR1 memory in bytes.
- Returns: Union[int, NaType]
Total free BAR1 memory in bytes, or
nvitop.NAwhen not applicable.
- bar1_memory_total_human() str | NaType[source]
Total BAR1 memory in human-readable format.
- Returns: Union[int, NaType]
Total BAR1 memory in human-readable format, or
nvitop.NAwhen not applicable.
- bar1_memory_used_human() str | NaType[source]
Total used BAR1 memory in human-readable format.
- Returns: Union[int, NaType]
Total used BAR1 memory in human-readable format, or
nvitop.NAwhen not applicable.
- bar1_memory_free_human() str | NaType[source]
Total free BAR1 memory in human-readable format.
- Returns: Union[int, NaType]
Total free BAR1 memory in human-readable format, or
nvitop.NAwhen not applicable.
- bar1_memory_percent() float | NaType[source]
The percentage of used BAR1 memory over total BAR1 memory (0 <= p <= 100).
- Returns: Union[float, NaType]
The percentage of used BAR1 memory over total BAR1 memory, or
nvitop.NAwhen not applicable.
- bar1_memory_usage() str[source]
The used BAR1 memory over total BAR1 memory in human-readable format.
- Returns: str
The used BAR1 memory over total BAR1 memory in human-readable format, or
'N/A / N/A'when not applicable.
- utilization_rates() UtilizationRates[source]
Return a named tuple with GPU utilization rates (in percentage) for the device.
- Returns: UtilizationRates(gpu, memory, encoder, decoder)
A named tuple with GPU utilization rates (in percentage) for the device, the item could be
nvitop.NAwhen not applicable.
- gpu_utilization() int | NaType[source]
Percent of time over the past sample period during which one or more kernels was executing on the GPU.
The sample period may be between 1 second and 1/6 second depending on the product.
- Returns: Union[int, NaType]
The GPU utilization rate in percentage, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=utilization.gpu
- gpu_percent() int | NaType
Percent of time over the past sample period during which one or more kernels was executing on the GPU.
The sample period may be between 1 second and 1/6 second depending on the product.
- Returns: Union[int, NaType]
The GPU utilization rate in percentage, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=utilization.gpu
- memory_utilization() int | NaType[source]
Percent of time over the past sample period during which global (device) memory was being read or written.
The sample period may be between 1 second and 1/6 second depending on the product.
- Returns: Union[int, NaType]
The memory bandwidth utilization rate of the GPU in percentage, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=utilization.memory
- encoder_utilization() int | NaType[source]
The encoder utilization rate in percentage.
- Returns: Union[int, NaType]
The encoder utilization rate in percentage, or
nvitop.NAwhen not applicable.
- decoder_utilization() int | NaType[source]
The decoder utilization rate in percentage.
- Returns: Union[int, NaType]
The decoder utilization rate in percentage, or
nvitop.NAwhen not applicable.
- clock_infos() ClockInfos[source]
Return a named tuple with current clock speeds (in MHz) for the device.
- Returns: ClockInfos(graphics, sm, memory, video)
A named tuple with current clock speeds (in MHz) for the device, the item could be
nvitop.NAwhen not applicable.
- clocks() ClockInfos
Return a named tuple with current clock speeds (in MHz) for the device.
- Returns: ClockInfos(graphics, sm, memory, video)
A named tuple with current clock speeds (in MHz) for the device, the item could be
nvitop.NAwhen not applicable.
- max_clock_infos() ClockInfos[source]
Return a named tuple with maximum clock speeds (in MHz) for the device.
- Returns: ClockInfos(graphics, sm, memory, video)
A named tuple with maximum clock speeds (in MHz) for the device, the item could be
nvitop.NAwhen not applicable.
- max_clocks() ClockInfos
Return a named tuple with maximum clock speeds (in MHz) for the device.
- Returns: ClockInfos(graphics, sm, memory, video)
A named tuple with maximum clock speeds (in MHz) for the device, the item could be
nvitop.NAwhen not applicable.
- clock_speed_infos() ClockSpeedInfos[source]
Return a named tuple with the current and the maximum clock speeds (in MHz) for the device.
- Returns: ClockSpeedInfos(current, max)
A named tuple with the current and the maximum clock speeds (in MHz) for the device.
- graphics_clock() int | NaType[source]
Current frequency of graphics (shader) clock in MHz.
- Returns: Union[int, NaType]
The current frequency of graphics (shader) clock in MHz, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=clocks.current.graphics
- sm_clock() int | NaType[source]
Current frequency of SM (Streaming Multiprocessor) clock in MHz.
- Returns: Union[int, NaType]
The current frequency of SM (Streaming Multiprocessor) clock in MHz, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=clocks.current.sm
- memory_clock() int | NaType[source]
Current frequency of memory clock in MHz.
- Returns: Union[int, NaType]
The current frequency of memory clock in MHz, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=clocks.current.memory
- video_clock() int | NaType[source]
Current frequency of video encoder/decoder clock in MHz.
- Returns: Union[int, NaType]
The current frequency of video encoder/decoder clock in MHz, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=clocks.current.video
- max_graphics_clock() int | NaType[source]
Maximum frequency of graphics (shader) clock in MHz.
- Returns: Union[int, NaType]
The maximum frequency of graphics (shader) clock in MHz, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=clocks.max.graphics
- max_sm_clock() int | NaType[source]
Maximum frequency of SM (Streaming Multiprocessor) clock in MHz.
- Returns: Union[int, NaType]
The maximum frequency of SM (Streaming Multiprocessor) clock in MHz, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=clocks.max.sm
- max_memory_clock() int | NaType[source]
Maximum frequency of memory clock in MHz.
- Returns: Union[int, NaType]
The maximum frequency of memory clock in MHz, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=clocks.max.memory
- max_video_clock() int | NaType[source]
Maximum frequency of video encoder/decoder clock in MHz.
- Returns: Union[int, NaType]
The maximum frequency of video encoder/decoder clock in MHz, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=clocks.max.video
- fan_speed() int | NaType[source]
The fan speed value is the percent of the product’s maximum noise tolerance fan speed that the device’s fan is currently intended to run at.
This value may exceed 100% in certain cases. Note: The reported speed is the intended fan speed. If the fan is physically blocked and unable to spin, this output will not match the actual fan speed. Many parts do not report fan speeds because they rely on cooling via fans in the surrounding enclosure.
- Returns: Union[int, NaType]
The fan speed value in percentage, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=fan.speed
- temperature() int | NaType[source]
Core GPU temperature in degrees C.
- Returns: Union[int, NaType]
The core GPU temperature in Celsius degrees, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=temperature.gpu
- power_usage() int | NaType[source]
The last measured power draw for the entire board in milliwatts.
- Returns: Union[int, NaType]
The power draw for the entire board in milliwatts, or
nvitop.NAwhen not applicable.
Command line equivalent:
$(( "$(nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=power.draw)" * 1000 ))
- power_draw() int | NaType
The last measured power draw for the entire board in milliwatts.
- Returns: Union[int, NaType]
The power draw for the entire board in milliwatts, or
nvitop.NAwhen not applicable.
Command line equivalent:
$(( "$(nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=power.draw)" * 1000 ))
- power_limit() int | NaType[source]
The software power limit in milliwatts.
Set by software like nvidia-smi.
- Returns: Union[int, NaType]
The software power limit in milliwatts, or
nvitop.NAwhen not applicable.
Command line equivalent:
$(( "$(nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=power.limit)" * 1000 ))
- power_status() str[source]
The string of power usage over power limit in watts.
- Returns: str
The string of power usage over power limit in watts, or
'N/A / N/A'when not applicable.
- pcie_throughput() ThroughputInfo[source]
The current PCIe throughput in KiB/s.
This function is querying a byte counter over a 20ms interval and thus is the PCIe throughput over that interval.
- Returns: ThroughputInfo(tx, rx)
A named tuple with current PCIe throughput in KiB/s, the item could be
nvitop.NAwhen not applicable.
- pcie_tx_throughput() int | NaType[source]
The current PCIe transmit throughput in KiB/s.
This function is querying a byte counter over a 20ms interval and thus is the PCIe throughput over that interval.
- Returns: Union[int, NaType]
The current PCIe transmit throughput in KiB/s, or
nvitop.NAwhen not applicable.
- pcie_rx_throughput() int | NaType[source]
The current PCIe receive throughput in KiB/s.
This function is querying a byte counter over a 20ms interval and thus is the PCIe throughput over that interval.
- Returns: Union[int, NaType]
The current PCIe receive throughput in KiB/s, or
nvitop.NAwhen not applicable.
- pcie_tx_throughput_human() str | NaType[source]
The current PCIe transmit throughput in human-readable format.
This function is querying a byte counter over a 20ms interval and thus is the PCIe throughput over that interval.
- Returns: Union[str, NaType]
The current PCIe transmit throughput in human-readable format, or
nvitop.NAwhen not applicable.
- pcie_rx_throughput_human() str | NaType[source]
The current PCIe receive throughput in human-readable format.
This function is querying a byte counter over a 20ms interval and thus is the PCIe throughput over that interval.
- Returns: Union[str, NaType]
The current PCIe receive throughput in human-readable format, or
nvitop.NAwhen not applicable.
- nvlink_link_count() int[source]
The number of NVLinks that the GPU has.
- Returns: Union[int, NaType]
The number of NVLinks that the GPU has.
- nvlink_throughput(interval: float | None = None) list[ThroughputInfo][source]
The current NVLink throughput for each NVLink in KiB/s.
This function is querying data counters between methods calls and thus is the NVLink throughput over that interval. For the first call, the function is blocking for 20ms to get the first data counters.
- Parameters:
interval (Optional[float]) – The interval in seconds between two calls to get the NVLink throughput. If
intervalis a positive number, compares throughput counters before and after the interval (blocking). Ifintervalis :const`0.0` orNone, compares throughput counters since the last call, returning immediately (non-blocking).
- Returns: List[ThroughputInfo(tx, rx)]
A list of named tuples with current NVLink throughput for each NVLink in KiB/s, the item could be
nvitop.NAwhen not applicable.
- nvlink_total_throughput(interval: float | None = None) ThroughputInfo[source]
The total NVLink throughput for all NVLinks in KiB/s.
This function is querying data counters between methods calls and thus is the NVLink throughput over that interval. For the first call, the function is blocking for 20ms to get the first data counters.
- Parameters:
interval (Optional[float]) – The interval in seconds between two calls to get the NVLink throughput. If
intervalis a positive number, compares throughput counters before and after the interval (blocking). Ifintervalis :const`0.0` orNone, compares throughput counters since the last call, returning immediately (non-blocking).
- Returns: ThroughputInfo(tx, rx)
A named tuple with the total NVLink throughput for all NVLinks in KiB/s, the item could be
nvitop.NAwhen not applicable.
- nvlink_mean_throughput(interval: float | None = None) ThroughputInfo[source]
The mean NVLink throughput for all NVLinks in KiB/s.
This function is querying data counters between methods calls and thus is the NVLink throughput over that interval. For the first call, the function is blocking for 20ms to get the first data counters.
- Parameters:
interval (Optional[float]) – The interval in seconds between two calls to get the NVLink throughput. If
intervalis a positive number, compares throughput counters before and after the interval (blocking). Ifintervalis :const`0.0` orNone, compares throughput counters since the last call, returning immediately (non-blocking).
- Returns: ThroughputInfo(tx, rx)
A named tuple with the mean NVLink throughput for all NVLinks in KiB/s, the item could be
nvitop.NAwhen not applicable.
- nvlink_tx_throughput(interval: float | None = None) list[int | NaType][source]
The current NVLink transmit data throughput in KiB/s for each NVLink.
This function is querying data counters between methods calls and thus is the NVLink throughput over that interval. For the first call, the function is blocking for 20ms to get the first data counters.
- Parameters:
interval (Optional[float]) – The interval in seconds between two calls to get the NVLink throughput. If
intervalis a positive number, compares throughput counters before and after the interval (blocking). Ifintervalis :const`0.0` orNone, compares throughput counters since the last call, returning immediately (non-blocking).
- Returns: List[Union[int, NaType]]
The current NVLink transmit data throughput in KiB/s for each NVLink, or
nvitop.NAwhen not applicable.
- nvlink_mean_tx_throughput(interval: float | None = None) int | NaType[source]
The mean NVLink transmit data throughput for all NVLinks in KiB/s.
This function is querying data counters between methods calls and thus is the NVLink throughput over that interval. For the first call, the function is blocking for 20ms to get the first data counters.
- Parameters:
interval (Optional[float]) – The interval in seconds between two calls to get the NVLink throughput. If
intervalis a positive number, compares throughput counters before and after the interval (blocking). Ifintervalis :const`0.0` orNone, compares throughput counters since the last call, returning immediately (non-blocking).
- Returns: Union[int, NaType]
The mean NVLink transmit data throughput for all NVLinks in KiB/s, or
nvitop.NAwhen not applicable.
- nvlink_total_tx_throughput(interval: float | None = None) int | NaType[source]
The total NVLink transmit data throughput for all NVLinks in KiB/s.
This function is querying data counters between methods calls and thus is the NVLink throughput over that interval. For the first call, the function is blocking for 20ms to get the first data counters.
- Parameters:
interval (Optional[float]) – The interval in seconds between two calls to get the NVLink throughput. If
intervalis a positive number, compares throughput counters before and after the interval (blocking). Ifintervalis :const`0.0` orNone, compares throughput counters since the last call, returning immediately (non-blocking).
- Returns: Union[int, NaType]
The total NVLink transmit data throughput for all NVLinks in KiB/s, or
nvitop.NAwhen not applicable.
- nvlink_rx_throughput(interval: float | None = None) list[int | NaType][source]
The current NVLink receive data throughput for each NVLink in KiB/s.
This function is querying data counters between methods calls and thus is the NVLink throughput over that interval. For the first call, the function is blocking for 20ms to get the first data counters.
- Parameters:
interval (Optional[float]) – The interval in seconds between two calls to get the NVLink throughput. If
intervalis a positive number, compares throughput counters before and after the interval (blocking). Ifintervalis :const`0.0` orNone, compares throughput counters since the last call, returning immediately (non-blocking).
- Returns: Union[int, NaType]
The current NVLink receive data throughput for each NVLink in KiB/s, or
nvitop.NAwhen not applicable.
- nvlink_mean_rx_throughput(interval: float | None = None) int | NaType[source]
The mean NVLink receive data throughput for all NVLinks in KiB/s.
This function is querying data counters between methods calls and thus is the NVLink throughput over that interval. For the first call, the function is blocking for 20ms to get the first data counters.
- Parameters:
interval (Optional[float]) – The interval in seconds between two calls to get the NVLink throughput. If
intervalis a positive number, compares throughput counters before and after the interval (blocking). Ifintervalis :const`0.0` orNone, compares throughput counters since the last call, returning immediately (non-blocking).
- Returns: Union[int, NaType]
The mean NVLink receive data throughput for all NVLinks in KiB/s, or
nvitop.NAwhen not applicable.
- nvlink_total_rx_throughput(interval: float | None = None) int | NaType[source]
The total NVLink receive data throughput for all NVLinks in KiB/s.
This function is querying data counters between methods calls and thus is the NVLink throughput over that interval. For the first call, the function is blocking for 20ms to get the first data counters.
- Parameters:
interval (Optional[float]) – The interval in seconds between two calls to get the NVLink throughput. If
intervalis a positive number, compares throughput counters before and after the interval (blocking). Ifintervalis :const`0.0` orNone, compares throughput counters since the last call, returning immediately (non-blocking).
- Returns: Union[int, NaType]
The total NVLink receive data throughput for all NVLinks in KiB/s, or
nvitop.NAwhen not applicable.
- nvlink_tx_throughput_human(interval: float | None = None) list[str | NaType][source]
The current NVLink transmit data throughput for each NVLink in human-readable format.
This function is querying data counters between methods calls and thus is the NVLink throughput over that interval. For the first call, the function is blocking for 20ms to get the first data counters.
- Parameters:
interval (Optional[float]) – The interval in seconds between two calls to get the NVLink throughput. If
intervalis a positive number, compares throughput counters before and after the interval (blocking). Ifintervalis :const`0.0` orNone, compares throughput counters since the last call, returning immediately (non-blocking).
- Returns: Union[str, NaType]
The current NVLink transmit data throughput for each NVLink in human-readable format, or
nvitop.NAwhen not applicable.
- nvlink_mean_tx_throughput_human(interval: float | None = None) str | NaType[source]
The mean NVLink transmit data throughput for all NVLinks in human-readable format.
This function is querying data counters between methods calls and thus is the NVLink throughput over that interval. For the first call, the function is blocking for 20ms to get the first data counters.
- Parameters:
interval (Optional[float]) – The interval in seconds between two calls to get the NVLink throughput. If
intervalis a positive number, compares throughput counters before and after the interval (blocking). Ifintervalis :const`0.0` orNone, compares throughput counters since the last call, returning immediately (non-blocking).
- Returns: Union[str, NaType]
The mean NVLink transmit data throughput for all NVLinks in human-readable format, or
nvitop.NAwhen not applicable.
- nvlink_total_tx_throughput_human(interval: float | None = None) str | NaType[source]
The total NVLink transmit data throughput for all NVLinks in human-readable format.
This function is querying data counters between methods calls and thus is the NVLink throughput over that interval. For the first call, the function is blocking for 20ms to get the first data counters.
- Parameters:
interval (Optional[float]) – The interval in seconds between two calls to get the NVLink throughput. If
intervalis a positive number, compares throughput counters before and after the interval (blocking). Ifintervalis :const`0.0` orNone, compares throughput counters since the last call, returning immediately (non-blocking).
- Returns: Union[str, NaType]
The total NVLink transmit data throughput for all NVLinks in human-readable format, or
nvitop.NAwhen not applicable.
- nvlink_rx_throughput_human(interval: float | None = None) list[str | NaType][source]
The current NVLink receive data throughput for each NVLink in human-readable format.
This function is querying data counters between methods calls and thus is the NVLink throughput over that interval. For the first call, the function is blocking for 20ms to get the first data counters.
- Parameters:
interval (Optional[float]) – The interval in seconds between two calls to get the NVLink throughput. If
intervalis a positive number, compares throughput counters before and after the interval (blocking). Ifintervalis :const`0.0` orNone, compares throughput counters since the last call, returning immediately (non-blocking).
- Returns: Union[str, NaType]
The current NVLink receive data throughput for each NVLink in human-readable format, or
nvitop.NAwhen not applicable.
- nvlink_mean_rx_throughput_human(interval: float | None = None) str | NaType[source]
The mean NVLink receive data throughput for all NVLinks in human-readable format.
This function is querying data counters between methods calls and thus is the NVLink throughput over that interval. For the first call, the function is blocking for 20ms to get the first data counters.
- Parameters:
interval (Optional[float]) – The interval in seconds between two calls to get the NVLink throughput. If
intervalis a positive number, compares throughput counters before and after the interval (blocking). Ifintervalis :const`0.0` orNone, compares throughput counters since the last call, returning immediately (non-blocking).
- Returns: Union[str, NaType]
The mean NVLink receive data throughput for all NVLinks in human-readable format, or
nvitop.NAwhen not applicable.
- nvlink_total_rx_throughput_human(interval: float | None = None) str | NaType[source]
The total NVLink receive data throughput for all NVLinks in human-readable format.
This function is querying data counters between methods calls and thus is the NVLink throughput over that interval. For the first call, the function is blocking for 20ms to get the first data counters.
- Parameters:
interval (Optional[float]) – The interval in seconds between two calls to get the NVLink throughput. If
intervalis a positive number, compares throughput counters before and after the interval (blocking). Ifintervalis :const`0.0` orNone, compares throughput counters since the last call, returning immediately (non-blocking).
- Returns: Union[str, NaType]
The total NVLink receive data throughput for all NVLinks in human-readable format, or
nvitop.NAwhen not applicable.
- display_active() str | NaType[source]
A flag that indicates whether a display is initialized on the GPU’s (e.g. memory is allocated on the device for display).
Display can be active even when no monitor is physically attached. “Enabled” indicates an active display. “Disabled” indicates otherwise.
- Returns: Union[str, NaType]
'Disabled': if not an active display device.'Enabled': if an active display device.nvitop.NA: if not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=display_active
- display_mode() str | NaType[source]
A flag that indicates whether a physical display (e.g. monitor) is currently connected to any of the GPU’s connectors.
“Enabled” indicates an attached display. “Disabled” indicates otherwise.
- Returns: Union[str, NaType]
'Disabled': if the display mode is disabled.'Enabled': if the display mode is enabled.nvitop.NA: if not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=display_mode
- current_driver_model() str | NaType[source]
The driver model currently in use.
Always “N/A” on Linux. On Windows, the TCC (WDM) and WDDM driver models are supported. The TCC driver model is optimized for compute applications. I.E. kernel launch times will be quicker with TCC. The WDDM driver model is designed for graphics applications and is not recommended for compute applications. Linux does not support multiple driver models, and will always have the value of “N/A”.
- Returns: Union[str, NaType]
'WDDM': for WDDM driver model on Windows.'WDM': for TTC (WDM) driver model on Windows.nvitop.NA: if not applicable, e.g. on Linux.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=driver_model.current
- driver_model() str | NaType
The driver model currently in use.
Always “N/A” on Linux. On Windows, the TCC (WDM) and WDDM driver models are supported. The TCC driver model is optimized for compute applications. I.E. kernel launch times will be quicker with TCC. The WDDM driver model is designed for graphics applications and is not recommended for compute applications. Linux does not support multiple driver models, and will always have the value of “N/A”.
- Returns: Union[str, NaType]
'WDDM': for WDDM driver model on Windows.'WDM': for TTC (WDM) driver model on Windows.nvitop.NA: if not applicable, e.g. on Linux.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=driver_model.current
- persistence_mode() str | NaType[source]
A flag that indicates whether persistence mode is enabled for the GPU. Value is either “Enabled” or “Disabled”.
When persistence mode is enabled the NVIDIA driver remains loaded even when no active clients, such as X11 or nvidia-smi, exist. This minimizes the driver load latency associated with running dependent apps, such as CUDA programs. Linux only.
- Returns: Union[str, NaType]
'Disabled': if the persistence mode is disabled.'Enabled': if the persistence mode is enabled.nvitop.NA: if not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=persistence_mode
- performance_state() str | NaType[source]
The current performance state for the GPU. States range from P0 (maximum performance) to P12 (minimum performance).
- Returns: Union[str, NaType]
The current performance state in format
P<int>, ornvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=pstate
- total_volatile_uncorrected_ecc_errors() int | NaType[source]
Total errors detected across entire chip.
- Returns: Union[int, NaType]
The total number of uncorrected errors in volatile ECC memory, or
nvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=ecc.errors.uncorrected.volatile.total
- compute_mode() str | NaType[source]
The compute mode flag indicates whether individual or multiple compute applications may run on the GPU.
- Returns: Union[str, NaType]
'Default': means multiple contexts are allowed per device.'Exclusive Thread': deprecated, use Exclusive Process instead'Prohibited': means no contexts are allowed per device (no compute apps).'Exclusive Process': means only one context is allowed per device, usable from multiple threads at a time.nvitop.NA: if not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=compute_mode
- cuda_compute_capability() tuple[int, int] | NaType[source]
The CUDA compute capability for the device.
- Returns: Union[Tuple[int, int], NaType]
The CUDA compute capability version in format
(major, minor), ornvitop.NAwhen not applicable.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=compute_cap
- mig_mode() str | NaType[source]
The MIG mode that the GPU is currently operating under.
- Returns: Union[str, NaType]
'Disabled': if the MIG mode is disabled.'Enabled': if the MIG mode is enabled.nvitop.NA: if not applicable, e.g. the GPU does not support MIG mode.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=mig.mode.current
- is_mig_mode_enabled() bool[source]
Test whether the MIG mode is enabled on the device.
Return
Falseif MIG mode is disabled or the device does not support MIG mode.
- max_mig_device_count() int[source]
Return the maximum number of MIG instances the device supports.
This method will return 0 if the device does not support MIG mode.
- mig_devices() list[MigDevice][source]
Return a list of children MIG devices of the current device.
This method will return an empty list if the MIG mode is disabled or the device does not support MIG mode.
- is_leaf_device() bool[source]
Test whether the device is a physical device with MIG mode disabled or a MIG device.
Return
Trueif the device is a physical device with MIG mode disabled or a MIG device. Otherwise, returnFalseif the device is a physical device with MIG mode enabled.
- to_leaf_devices() list[PhysicalDevice] | list[MigDevice] | list[CudaDevice] | list[CudaMigDevice][source]
Return a list of leaf devices.
Note that a CUDA device is always a leaf device.
- processes() dict[int, GpuProcess][source]
Return a dictionary of processes running on the GPU.
- Returns: Dict[int, GpuProcess]
A dictionary mapping PID to GPU process instance.
- as_snapshot() Snapshot[source]
Return a one-time snapshot of the device.
The attributes are defined in
SNAPSHOT_KEYS.
- SNAPSHOT_KEYS: ClassVar[list[str]] = ['name', 'uuid', 'bus_id', 'memory_info', 'memory_used', 'memory_free', 'memory_total', 'memory_used_human', 'memory_free_human', 'memory_total_human', 'memory_percent', 'memory_usage', 'utilization_rates', 'gpu_utilization', 'memory_utilization', 'encoder_utilization', 'decoder_utilization', 'clock_infos', 'max_clock_infos', 'clock_speed_infos', 'sm_clock', 'memory_clock', 'fan_speed', 'temperature', 'power_usage', 'power_limit', 'power_status', 'pcie_throughput', 'pcie_tx_throughput', 'pcie_rx_throughput', 'pcie_tx_throughput_human', 'pcie_rx_throughput_human', 'display_active', 'display_mode', 'current_driver_model', 'persistence_mode', 'performance_state', 'total_volatile_uncorrected_ecc_errors', 'compute_mode', 'cuda_compute_capability', 'mig_mode']
- oneshot() Generator[None][source]
A utility context manager which considerably speeds up the retrieval of multiple device information at the same time.
Internally different device info (e.g. memory_info, utilization_rates, …) may be fetched by using the same routine, but only one information is returned and the others are discarded. When using this context manager the internal routine is executed once (in the example below on memory_info()) and the other info are cached.
The cache is cleared when exiting the context manager block. The advice is to use this every time you retrieve more than one information about the device.
Examples
>>> from nvitop import Device >>> device = Device(0) >>> with device.oneshot(): ... device.memory_info() # collect multiple info ... device.memory_used() # return cached value ... device.memory_free_human() # return cached value ... device.memory_percent() # return cached value
- class nvitop.PhysicalDevice(index: int | tuple[int, int] | str | None = None, *, uuid: str | None = None, bus_id: str | None = None)[source]
Bases:
DeviceClass for physical devices.
This is the real GPU installed in the system.
- property physical_index: int
Zero based index of the GPU. Can change at each boot.
Command line equivalent:
nvidia-smi --id=<IDENTIFIER> --format=csv,noheader,nounits --query-gpu=index
- max_mig_device_count() int[source]
Return the maximum number of MIG instances the device supports.
This method will return 0 if the device does not support MIG mode.
- mig_device(mig_index: int) MigDevice[source]
Return a child MIG device of the given index.
- Raises:
libnvml.NVMLError – If the device does not support MIG mode or the given MIG device does not exist.
- class nvitop.MigDevice(index: int | tuple[int, int] | str | None = None, *, uuid: str | None = None, bus_id: str | None = None)[source]
Bases:
DeviceClass for MIG devices.
- classmethod count() int[source]
The number of total MIG devices aggregated over all physical devices.
- classmethod all() list[MigDevice][source]
Return a list of MIG devices aggregated over all physical devices.
- classmethod from_indices(indices: Iterable[tuple[int, int]]) list[MigDevice][source]
Return a list of MIG devices of the given indices.
- Parameters:
indices (Iterable[Tuple[int, int]]) – Indices of the MIG devices. Each index is a tuple of two integers.
- Returns: List[MigDevice]
A list of
MigDeviceinstances of the given indices.
- Raises:
libnvml.NVMLError_LibraryNotFound – If cannot find the NVML library, usually the NVIDIA driver is not installed.
libnvml.NVMLError_DriverNotLoaded – If NVIDIA driver is not loaded.
libnvml.NVMLError_LibRmVersionMismatch – If RM detects a driver/library version mismatch, usually after an upgrade for NVIDIA driver without reloading the kernel module.
libnvml.NVMLError_NotFound – If the device is not found for the given NVML identifier.
- __init__(index: tuple[int, int] | str | None = None, *, uuid: str | None = None) None[source]
Initialize the instance created by
__new__().- Raises:
libnvml.NVMLError_LibraryNotFound – If cannot find the NVML library, usually the NVIDIA driver is not installed.
libnvml.NVMLError_DriverNotLoaded – If NVIDIA driver is not loaded.
libnvml.NVMLError_LibRmVersionMismatch – If RM detects a driver/library version mismatch, usually after an upgrade for NVIDIA driver without reloading the kernel module.
libnvml.NVMLError_NotFound – If the device is not found for the given NVML identifier.
- property physical_index: int
The index of the parent physical device.
- property mig_index: int
The index of the MIG device over the all MIG devices of the parent device.
- property parent: PhysicalDevice
The parent physical device.
- gpu_instance_id() int | NaType[source]
The gpu instance ID of the MIG device.
- Returns: Union[int, NaType]
The gpu instance ID of the MIG device, or
nvitop.NAwhen not applicable.
- compute_instance_id() int | NaType[source]
The compute instance ID of the MIG device.
- Returns: Union[int, NaType]
The compute instance ID of the MIG device, or
nvitop.NAwhen not applicable.
- as_snapshot() Snapshot[source]
Return a one-time snapshot of the device.
The attributes are defined in
SNAPSHOT_KEYS.
- SNAPSHOT_KEYS: ClassVar[list[str]] = ['name', 'uuid', 'bus_id', 'memory_info', 'memory_used', 'memory_free', 'memory_total', 'memory_used_human', 'memory_free_human', 'memory_total_human', 'memory_percent', 'memory_usage', 'utilization_rates', 'gpu_utilization', 'memory_utilization', 'encoder_utilization', 'decoder_utilization', 'clock_infos', 'max_clock_infos', 'clock_speed_infos', 'sm_clock', 'memory_clock', 'fan_speed', 'temperature', 'power_usage', 'power_limit', 'power_status', 'pcie_throughput', 'pcie_tx_throughput', 'pcie_rx_throughput', 'pcie_tx_throughput_human', 'pcie_rx_throughput_human', 'display_active', 'display_mode', 'current_driver_model', 'persistence_mode', 'performance_state', 'total_volatile_uncorrected_ecc_errors', 'compute_mode', 'cuda_compute_capability', 'mig_mode', 'gpu_instance_id', 'compute_instance_id']
- class nvitop.CudaDevice(cuda_index: int | None = None, *, nvml_index: int | tuple[int, int] | None = None, uuid: str | None = None)[source]
Bases:
DeviceClass for devices enumerated over the CUDA ordinal.
The order can be vary for different
CUDA_VISIBLE_DEVICESenvironment variable.- See also for CUDA Device Enumeration:
CudaDevice.__new__()returns different types depending on the given arguments.- (cuda_index: int) -> Union[CudaDevice, CudaMigDevice] # depending on `CUDA_VISIBLE_DEVICES` - (uuid: str) -> Union[CudaDevice, CudaMigDevice] # depending on `CUDA_VISIBLE_DEVICES` - (nvml_index: int) -> CudaDevice - (nvml_index: (int, int)) -> CudaMigDevice
Examples
>>> import os >>> os.environ['CUDA_DEVICE_ORDER'] = 'PCI_BUS_ID' >>> os.environ['CUDA_VISIBLE_DEVICES'] = '3,2,1,0'
>>> CudaDevice.count() # number of NVIDIA GPUs visible to CUDA applications 4 >>> Device.cuda.count() # use alias in class `Device` 4
>>> CudaDevice.all() # all CUDA visible devices (or `Device.cuda.all()`) [ CudaDevice(cuda_index=0, nvml_index=3, ...), CudaDevice(cuda_index=1, nvml_index=2, ...), ... ]
>>> cuda0 = CudaDevice(cuda_index=0) # use CUDA ordinal (or `Device.cuda(0)`) >>> cuda1 = CudaDevice(nvml_index=2) # use NVML ordinal >>> cuda2 = CudaDevice(uuid='GPU-xxxxxx') # use UUID string
>>> cuda0.memory_free() # total free memory in bytes 11550654464 >>> cuda0.memory_free_human() # total free memory in human-readable format '11016MiB'
>>> cuda1.as_snapshot() # takes a one-time snapshot of the device CudaDeviceSnapshot( real=CudaDevice(cuda_index=1, nvml_index=2, ...), ... )
- Raises:
libnvml.NVMLError_LibraryNotFound – If cannot find the NVML library, usually the NVIDIA driver is not installed.
libnvml.NVMLError_DriverNotLoaded – If NVIDIA driver is not loaded.
libnvml.NVMLError_LibRmVersionMismatch – If RM detects a driver/library version mismatch, usually after an upgrade for NVIDIA driver without reloading the kernel module.
libnvml.NVMLError_NotFound – If the device is not found for the given NVML identifier.
libnvml.NVMLError_InvalidArgument – If the NVML index is out of range.
TypeError – If the number of non-None arguments is not exactly 1.
TypeError – If the given NVML index is a tuple but does not consist of two integers.
RuntimeError – If the index is out of range for the given
CUDA_VISIBLE_DEVICESenvironment variable.
- classmethod all() list[CudaDevice][source]
All CUDA visible devices.
Note
The result could be empty if the
CUDA_VISIBLE_DEVICESenvironment variable is invalid.
- classmethod from_indices(indices: int | Iterable[int] | None = None) list[CudaDevice][source]
Return a list of CUDA devices of the given CUDA indices.
The CUDA ordinal will be enumerate from the
CUDA_VISIBLE_DEVICESenvironment variable.- See also for CUDA Device Enumeration:
- Parameters:
indices (Iterable[int]) – The indices of the GPU in CUDA ordinal, if not given, returns all visible CUDA devices.
- Returns: List[CudaDevice]
A list of
CudaDeviceof the given CUDA indices.
- Raises:
libnvml.NVMLError_LibraryNotFound – If cannot find the NVML library, usually the NVIDIA driver is not installed.
libnvml.NVMLError_DriverNotLoaded – If NVIDIA driver is not loaded.
libnvml.NVMLError_LibRmVersionMismatch – If RM detects a driver/library version mismatch, usually after an upgrade for NVIDIA driver without reloading the kernel module.
RuntimeError – If the index is out of range for the given
CUDA_VISIBLE_DEVICESenvironment variable.
- static __new__(cls, cuda_index: int | None = None, *, nvml_index: int | tuple[int, int] | None = None, uuid: str | None = None) Self[source]
Create a new instance of CudaDevice.
The type of the result is determined by the given argument.
- (cuda_index: int) -> Union[CudaDevice, CudaMigDevice] # depending on `CUDA_VISIBLE_DEVICES` - (uuid: str) -> Union[CudaDevice, CudaMigDevice] # depending on `CUDA_VISIBLE_DEVICES` - (nvml_index: int) -> CudaDevice - (nvml_index: (int, int)) -> CudaMigDevice
Note: This method takes exactly 1 non-None argument.
- Returns: Union[CudaDevice, CudaMigDevice]
A
CudaDeviceinstance or aCudaMigDeviceinstance.
- Raises:
TypeError – If the number of non-None arguments is not exactly 1.
TypeError – If the given NVML index is a tuple but does not consist of two integers.
RuntimeError – If the index is out of range for the given
CUDA_VISIBLE_DEVICESenvironment variable.
- __init__(cuda_index: int | None = None, *, nvml_index: int | tuple[int, int] | None = None, uuid: str | None = None) None[source]
Initialize the instance created by
__new__().- Raises:
libnvml.NVMLError_LibraryNotFound – If cannot find the NVML library, usually the NVIDIA driver is not installed.
libnvml.NVMLError_DriverNotLoaded – If NVIDIA driver is not loaded.
libnvml.NVMLError_LibRmVersionMismatch – If RM detects a driver/library version mismatch, usually after an upgrade for NVIDIA driver without reloading the kernel module.
libnvml.NVMLError_NotFound – If the device is not found for the given NVML identifier.
libnvml.NVMLError_InvalidArgument – If the NVML index is out of range.
RuntimeError – If the given device is not visible to CUDA applications (i.e. not listed in the
CUDA_VISIBLE_DEVICESenvironment variable or the environment variable is invalid).
- class nvitop.CudaMigDevice(cuda_index: int | None = None, *, nvml_index: int | tuple[int, int] | None = None, uuid: str | None = None)[source]
Bases:
CudaDevice,MigDeviceClass for CUDA devices that are MIG devices.
- nvitop.parse_cuda_visible_devices(cuda_visible_devices: str | None = <VALUE OMITTED>) list[int] | list[tuple[int, int]][source]
Parse the given
CUDA_VISIBLE_DEVICESvalue into a list of NVML device indices.This function is aliased by
Device.parse_cuda_visible_devices().Note
The result could be empty if the
CUDA_VISIBLE_DEVICESenvironment variable is invalid.- See also for CUDA Device Enumeration:
- Parameters:
cuda_visible_devices (Optional[str]) – The value of the
CUDA_VISIBLE_DEVICESvariable. If not given, the value from the environment will be used. If explicitly given byNone, theCUDA_VISIBLE_DEVICESenvironment variable will be unset before parsing.
- Returns: Union[List[int], List[Tuple[int, int]]]
A list of int (physical device) or a list of tuple of two integers (MIG device) for the corresponding real device indices.
Examples
>>> import os >>> os.environ['CUDA_DEVICE_ORDER'] = 'PCI_BUS_ID' >>> os.environ['CUDA_VISIBLE_DEVICES'] = '6,5' >>> parse_cuda_visible_devices() # parse the `CUDA_VISIBLE_DEVICES` environment variable to NVML indices [6, 5]
>>> parse_cuda_visible_devices('0,4') # pass the `CUDA_VISIBLE_DEVICES` value explicitly [0, 4]
>>> parse_cuda_visible_devices('GPU-18ef14e9,GPU-849d5a8d') # accept abbreviated UUIDs [5, 6]
>>> parse_cuda_visible_devices(None) # get all devices when the `CUDA_VISIBLE_DEVICES` environment variable unset [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> parse_cuda_visible_devices('MIG-d184f67c-c95f-5ef2-a935-195bd0094fbd') # MIG device support (MIG UUID) [(0, 0)] >>> parse_cuda_visible_devices('MIG-GPU-3eb79704-1571-707c-aee8-f43ce747313d/13/0') # MIG device support (GPU UUID) [(0, 1)] >>> parse_cuda_visible_devices('MIG-GPU-3eb79704/13/0') # MIG device support (abbreviated GPU UUID) [(0, 1)]
>>> parse_cuda_visible_devices('') # empty string [] >>> parse_cuda_visible_devices('0,0') # invalid `CUDA_VISIBLE_DEVICES` (duplicate device ordinal) [] >>> parse_cuda_visible_devices('16') # invalid `CUDA_VISIBLE_DEVICES` (device ordinal out of range) []
- nvitop.normalize_cuda_visible_devices(cuda_visible_devices: str | None = <VALUE OMITTED>) str[source]
Parse the given
CUDA_VISIBLE_DEVICESvalue and convert it into a comma-separated string of UUIDs.This function is aliased by
Device.normalize_cuda_visible_devices().Note
The result could be empty string if the
CUDA_VISIBLE_DEVICESenvironment variable is invalid.- See also for CUDA Device Enumeration:
- Parameters:
cuda_visible_devices (Optional[str]) – The value of the
CUDA_VISIBLE_DEVICESvariable. If not given, the value from the environment will be used. If explicitly given byNone, theCUDA_VISIBLE_DEVICESenvironment variable will be unset before parsing.
- Returns: str
The comma-separated string (GPU UUIDs) of the
CUDA_VISIBLE_DEVICESenvironment variable.
Examples
>>> import os >>> os.environ['CUDA_DEVICE_ORDER'] = 'PCI_BUS_ID' >>> os.environ['CUDA_VISIBLE_DEVICES'] = '6,5' >>> normalize_cuda_visible_devices() # normalize the `CUDA_VISIBLE_DEVICES` environment variable to UUID strings 'GPU-849d5a8d-610e-eeea-1fd4-81ff44a23794,GPU-18ef14e9-dec6-1d7e-1284-3010c6ce98b1'
>>> normalize_cuda_visible_devices('4') # pass the `CUDA_VISIBLE_DEVICES` value explicitly 'GPU-96de99c9-d68f-84c8-424c-7c75e59cc0a0'
>>> normalize_cuda_visible_devices('GPU-18ef14e9,GPU-849d5a8d') # normalize abbreviated UUIDs 'GPU-18ef14e9-dec6-1d7e-1284-3010c6ce98b1,GPU-849d5a8d-610e-eeea-1fd4-81ff44a23794'
>>> normalize_cuda_visible_devices(None) # get all devices when the `CUDA_VISIBLE_DEVICES` environment variable unset 'GPU-<GPU0-UUID>,GPU-<GPU1-UUID>,...' # all GPU UUIDs
>>> normalize_cuda_visible_devices('MIG-d184f67c-c95f-5ef2-a935-195bd0094fbd') # MIG device support (MIG UUID) 'MIG-d184f67c-c95f-5ef2-a935-195bd0094fbd' >>> normalize_cuda_visible_devices('MIG-GPU-3eb79704-1571-707c-aee8-f43ce747313d/13/0') # MIG device support (GPU UUID) 'MIG-37b51284-1df4-5451-979d-3231ccb0822e' >>> normalize_cuda_visible_devices('MIG-GPU-3eb79704/13/0') # MIG device support (abbreviated GPU UUID) 'MIG-37b51284-1df4-5451-979d-3231ccb0822e'
>>> normalize_cuda_visible_devices('') # empty string '' >>> normalize_cuda_visible_devices('0,0') # invalid `CUDA_VISIBLE_DEVICES` (duplicate device ordinal) '' >>> normalize_cuda_visible_devices('16') # invalid `CUDA_VISIBLE_DEVICES` (device ordinal out of range) ''
- class nvitop.HostProcess(pid: int | None = None)[source]
-
Represent an OS process with the given PID.
If PID is omitted, the current process PID (
os.getpid()) is used. The instance will be cached during the lifetime of the process.Examples
>>> HostProcess() # the current process HostProcess(pid=12345, name='python3', status='running', started='00:55:43')
>>> p1 = HostProcess(12345) >>> p2 = HostProcess(12345) >>> p1 is p2 # the same instance True
>>> import copy >>> copy.deepcopy(p1) is p1 # the same instance True
>>> p = HostProcess(pid=12345) >>> p.cmdline() ['python3', '-c', 'import IPython; IPython.terminal.ipapp.launch_new_instance()'] >>> p.command() # the result is in shell-escaped format 'python3 -c "import IPython; IPython.terminal.ipapp.launch_new_instance()"'
>>> p.as_snapshot() HostProcessSnapshot( real=HostProcess(pid=12345, name='python3', status='running', started='00:55:43'), cmdline=['python3', '-c', 'import IPython; IPython.terminal.ipapp.launch_new_instance()'], command='python3 -c "import IPython; IPython.terminal.ipapp.launch_new_instance()"', connections=[], cpu_percent=0.3, cpu_times=pcputimes(user=2.180019456, system=0.18424464, children_user=0.0, children_system=0.0), create_time=1656608143.31, cwd='/home/panxuehai', environ={...}, ... )
- INSTANCE_LOCK: RLock = <unlocked _thread.RLock object owner=0 count=0>
- INSTANCES: WeakValueDictionary[int, HostProcess] = <WeakValueDictionary>
- static __new__(cls, pid: int | None = None) Self[source]
Return the cached instance of
HostProcess.
- username() str[source]
Return the name of the user that owns the process.
On UNIX this is calculated by using real process uid.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
- cmdline() list[str][source]
Return the command line this process has been called with.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
- command() str[source]
Return a shell-escaped string from command line arguments.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
- running_time() timedelta[source]
Return the elapsed time this process has been running as a
datetime.timedelta.- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
- running_time_human() str[source]
Return the elapsed time this process has been running in human-readable format.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
- running_time_in_seconds() float[source]
Return the elapsed time this process has been running in seconds.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
- elapsed_time() timedelta
Return the elapsed time this process has been running as a
datetime.timedelta.- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
- elapsed_time_human() str
Return the elapsed time this process has been running in human-readable format.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
- elapsed_time_in_seconds() float
Return the elapsed time this process has been running in seconds.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
- rss_memory() int[source]
Return the used resident set size (RSS) memory of the process in bytes.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
- parent() HostProcess | None[source]
Return the parent process as a
HostProcessinstance orNoneif there is no parent.- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
- children(recursive: bool = False) list[HostProcess][source]
Return the children of this process as a list of
HostProcessinstances.If recursive is
Truereturn all the descendants.- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
- oneshot() Generator[None][source]
A utility context manager which considerably speeds up the retrieval of multiple process information at the same time.
Internally different process info (e.g. name, ppid, uids, gids, …) may be fetched by using the same routine, but only one information is returned and the others are discarded. When using this context manager the internal routine is executed once (in the example below on
name()) and the other info are cached.The cache is cleared when exiting the context manager block. The advice is to use this every time you retrieve more than one information about the process.
Examples
>>> from nvitop import HostProcess >>> p = HostProcess() >>> with p.oneshot(): ... p.name() # collect multiple info ... p.cpu_times() # return cached value ... p.cpu_percent() # return cached value ... p.create_time() # return cached value
- class nvitop.GpuProcess(pid: int | None, device: Device, *, gpu_memory: int | NaType | None = None, gpu_instance_id: int | NaType | None = None, compute_instance_id: int | NaType | None = None, type: str | NaType | None = None)[source]
Bases:
objectRepresent a process with the given PID running on the given GPU device.
The instance will be cached during the lifetime of the process.
The same host process can use multiple GPU devices. The
GpuProcessinstances representing the same PID on the host but different GPU devices are different.- INSTANCE_LOCK: threading.RLock = <unlocked _thread.RLock object owner=0 count=0>
- INSTANCES: WeakValueDictionary[tuple[int, Device], GpuProcess] = <WeakValueDictionary>
- static __new__(cls, pid: int | None, device: Device, *, gpu_memory: int | NaType | None = None, gpu_instance_id: int | NaType | None = None, compute_instance_id: int | NaType | None = None, type: str | NaType | None = None) Self[source]
Return the cached instance of
GpuProcess.
- __init__(pid: int | None, device: Device, *, gpu_memory: int | NaType | None = None, gpu_instance_id: int | NaType | None = None, compute_instance_id: int | NaType | None = None, type: str | NaType | None = None) None[source]
Initialize the instance returned by
__new__().
- __getattr__(name: str) Any | Callable[..., Any][source]
Get a member from the instance or fallback to the host process instance if missing.
- Raises:
AttributeError – If the attribute is not defined in either
GpuProcessorHostProcess.host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
- property pid: int
The process PID.
- property host: HostProcess
The process instance running on the host.
- property device: Device
The GPU device the process running on.
The same host process can use multiple GPU devices. The
GpuProcessinstances representing the same PID on the host but different GPU devices are different.
- gpu_instance_id() int | NaType[source]
Return the GPU instance ID of the MIG device, or
nvitop.NAif not applicable.
- compute_instance_id() int | NaType[source]
Return the compute instance ID of the MIG device, or
nvitop.NAif not applicable.
- gpu_memory() int | NaType[source]
Return the used GPU memory in bytes, or
nvitop.NAif not applicable.
- gpu_memory_human() str | NaType[source]
Return the used GPU memory in human-readable format, or
nvitop.NAif not applicable.
- gpu_memory_percent() float | NaType[source]
Return the percentage of used GPU memory by the process, or
nvitop.NAif not applicable.
- gpu_sm_utilization() int | NaType[source]
Return the utilization rate of SM (Streaming Multiprocessor), or
nvitop.NAif not applicable.
- gpu_memory_utilization() int | NaType[source]
Return the utilization rate of GPU memory bandwidth, or
nvitop.NAif not applicable.
- gpu_encoder_utilization() int | NaType[source]
Return the utilization rate of the encoder, or
nvitop.NAif not applicable.
- gpu_decoder_utilization() int | NaType[source]
Return the utilization rate of the decoder, or
nvitop.NAif not applicable.
- set_gpu_utilization(gpu_sm_utilization: int | NaType | None = None, gpu_memory_utilization: int | NaType | None = None, gpu_encoder_utilization: int | NaType | None = None, gpu_decoder_utilization: int | NaType | None = None) None[source]
Set the GPU utilization rates.
- property type: str | NaType
The type of the GPU context.
- The type is one of the following:
'C': compute context'G': graphics context'C+G': both compute context and graphics context'N/A': not applicable
- status() str[source]
Return the process current status.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
Note
To return the fallback value rather than raise an exception, please use the context manager
GpuProcess.failsafe(). See alsotake_snapshots()andfailsafe().
- create_time() float | NaType[source]
Return the process creation time as a floating point number expressed in seconds since the epoch.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
Note
To return the fallback value rather than raise an exception, please use the context manager
GpuProcess.failsafe(). See alsotake_snapshots()andfailsafe().
- running_time() timedelta | NaType[source]
Return the elapsed time this process has been running as a
datetime.timedelta.- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
Note
To return the fallback value rather than raise an exception, please use the context manager
GpuProcess.failsafe(). See alsotake_snapshots()andfailsafe().
- running_time_human() str | NaType[source]
Return the elapsed time this process has been running in human-readable format.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
Note
To return the fallback value rather than raise an exception, please use the context manager
GpuProcess.failsafe(). See alsotake_snapshots()andfailsafe().
- running_time_in_seconds() float | NaType[source]
Return the elapsed time this process has been running in seconds.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
Note
To return the fallback value rather than raise an exception, please use the context manager
GpuProcess.failsafe(). See alsotake_snapshots()andfailsafe().
- elapsed_time() timedelta | NaType
Return the elapsed time this process has been running as a
datetime.timedelta.- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
Note
To return the fallback value rather than raise an exception, please use the context manager
GpuProcess.failsafe(). See alsotake_snapshots()andfailsafe().
- elapsed_time_human() str | NaType
Return the elapsed time this process has been running in human-readable format.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
Note
To return the fallback value rather than raise an exception, please use the context manager
GpuProcess.failsafe(). See alsotake_snapshots()andfailsafe().
- elapsed_time_in_seconds() float | NaType
Return the elapsed time this process has been running in seconds.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
Note
To return the fallback value rather than raise an exception, please use the context manager
GpuProcess.failsafe(). See alsotake_snapshots()andfailsafe().
- username() str | NaType[source]
Return the name of the user that owns the process.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
Note
To return the fallback value rather than raise an exception, please use the context manager
GpuProcess.failsafe(). See alsotake_snapshots()andfailsafe().
- name() str | NaType[source]
Return the process name.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
Note
To return the fallback value rather than raise an exception, please use the context manager
GpuProcess.failsafe(). See alsotake_snapshots()andfailsafe().
- cpu_percent() float | NaType[source]
Return a float representing the current process CPU utilization as a percentage.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
Note
To return the fallback value rather than raise an exception, please use the context manager
GpuProcess.failsafe(). See alsotake_snapshots()andfailsafe().
- memory_percent() float | NaType[source]
Compare process RSS memory to total physical system memory and calculate process memory utilization as a percentage.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
Note
To return the fallback value rather than raise an exception, please use the context manager
GpuProcess.failsafe(). See alsotake_snapshots()andfailsafe().
- host_memory_percent() float | NaType
Compare process RSS memory to total physical system memory and calculate process memory utilization as a percentage.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
Note
To return the fallback value rather than raise an exception, please use the context manager
GpuProcess.failsafe(). See alsotake_snapshots()andfailsafe().
- host_memory() int | NaType[source]
Return the used resident set size (RSS) memory of the process in bytes.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
Note
To return the fallback value rather than raise an exception, please use the context manager
GpuProcess.failsafe(). See alsotake_snapshots()andfailsafe().
- host_memory_human() str | NaType[source]
Return the used resident set size (RSS) memory of the process in human-readable format.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
Note
To return the fallback value rather than raise an exception, please use the context manager
GpuProcess.failsafe(). See alsotake_snapshots()andfailsafe().
- rss_memory() int | NaType
Return the used resident set size (RSS) memory of the process in bytes.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
Note
To return the fallback value rather than raise an exception, please use the context manager
GpuProcess.failsafe(). See alsotake_snapshots()andfailsafe().
- cmdline() list[str][source]
Return the command line this process has been called with.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
Note
To return the fallback value rather than raise an exception, please use the context manager
GpuProcess.failsafe(). See alsotake_snapshots()andfailsafe().
- command() str[source]
Return a shell-escaped string from command line arguments.
- Raises:
host.NoSuchProcess – If the process is gone.
host.AccessDenied – If the user does not have read privilege to the process’ status file.
Note
To return the fallback value rather than raise an exception, please use the context manager
GpuProcess.failsafe(). See alsotake_snapshots()andfailsafe().
- as_snapshot(*, host_process_snapshot_cache: dict[int, Snapshot] | None = None) Snapshot[source]
Return a one-time snapshot of the process on the GPU device.
Note
To return the fallback value rather than raise an exception, please use the context manager
GpuProcess.failsafe(). Also, consider using the batched version to take snapshots withGpuProcess.take_snapshots(), which caches the results and reduces redundant queries. See alsotake_snapshots()andfailsafe().
- classmethod take_snapshots(gpu_processes: Iterable[GpuProcess], *, failsafe: bool = False) list[Snapshot][source]
Take snapshots for a list of
GpuProcessinstances.If failsafe is
True, then if any method fails, the fallback value inauto_garbage_clean()will be used.
- classmethod failsafe() Generator[None][source]
A context manager that enables fallback values for methods that fail.
Examples
>>> p = GpuProcess(pid=10000, device=Device(0)) # process does not exist >>> p GpuProcess(pid=10000, gpu_memory=N/A, type=N/A, device=PhysicalDevice(index=0, name="NVIDIA GeForce RTX 3070", total_memory=8192MiB), host=HostProcess(pid=10000, status='terminated')) >>> p.cpu_percent() Traceback (most recent call last): ... NoSuchProcess: process no longer exists (pid=10000)
>>> # Failsafe to the fallback value instead of raising exceptions ... with GpuProcess.failsafe(): ... print('fallback: {!r}'.format(p.cpu_percent())) ... print('fallback (float cast): {!r}'.format(float(p.cpu_percent()))) # `nvitop.NA` can be cast to float or int ... print('fallback (int cast): {!r}'.format(int(p.cpu_percent()))) # `nvitop.NA` can be cast to float or int fallback: 'N/A' fallback (float cast): nan fallback (int cast): 0
- nvitop.command_join(cmdline: list[str]) str[source]
Return a shell-escaped string from a list of command line arguments.
- nvitop.take_snapshots(devices: Device | Iterable[Device] | None = None, *, gpu_processes: bool | GpuProcess | Iterable[GpuProcess] | None = None) SnapshotResult[source]
Retrieve status of demanded devices and GPU processes.
- Parameters:
devices (Optional[Union[Device, Iterable[Device]]]) – Requested devices for snapshots. If not given, the devices will be determined from GPU processes: (1) All devices (no GPU processes are given); (2) Devices that used by given GPU processes.
gpu_processes (Optional[Union[bool, GpuProcess, Iterable[GpuProcess]]]) – Requested GPU processes snapshots. If not given, all GPU processes running on the requested device will be returned. The GPU process snapshots can be suppressed by specifying
gpu_processes=False.
- Returns: SnapshotResult
A named tuple containing two lists of snapshots.
Note
If no arguments are specified, all devices and all GPU processes will be returned.
Examples
>>> from nvitop import take_snapshots, Device >>> import os >>> os.environ['CUDA_DEVICE_ORDER'] = 'PCI_BUS_ID' >>> os.environ['CUDA_VISIBLE_DEVICES'] = '1,0'
>>> take_snapshots() # equivalent to `take_snapshots(Device.all())` SnapshotResult( devices=[ PhysicalDeviceSnapshot( real=PhysicalDevice(index=0, ...), ... ), ... ], gpu_processes=[ GpuProcessSnapshot( real=GpuProcess(pid=xxxxxx, device=PhysicalDevice(index=0, ...), ...), ... ), ... ] )
>>> device_snapshots, gpu_process_snapshots = take_snapshots(Device.all()) # type: Tuple[List[DeviceSnapshot], List[GpuProcessSnapshot]]
>>> device_snapshots, _ = take_snapshots(gpu_processes=False) # ignore process snapshots
>>> take_snapshots(Device.cuda.all()) # use CUDA device enumeration SnapshotResult( devices=[ CudaDeviceSnapshot( real=CudaDevice(cuda_index=0, physical_index=1, ...), ... ), CudaDeviceSnapshot( real=CudaDevice(cuda_index=1, physical_index=0, ...), ... ), ], gpu_processes=[ GpuProcessSnapshot( real=GpuProcess(pid=xxxxxx, device=CudaDevice(cuda_index=0, ...), ...), ... ), ... ] )
>>> take_snapshots(Device.cuda(1)) # <CUDA 1> only SnapshotResult( devices=[ CudaDeviceSnapshot( real=CudaDevice(cuda_index=1, physical_index=0, ...), ... ) ], gpu_processes=[ GpuProcessSnapshot( real=GpuProcess(pid=xxxxxx, device=CudaDevice(cuda_index=1, ...), ...), ... ), ... ] )
- nvitop.collect_in_background(on_collect: Callable[[dict[str, float]], bool], collector: ResourceMetricCollector | None = None, interval: float | None = None, *, on_start: Callable[[ResourceMetricCollector], None] | None = None, on_stop: Callable[[ResourceMetricCollector], None] | None = None, tag: str = 'metrics-daemon', start: bool = True) threading.Thread[source]
Start a background daemon thread that collect and call the callback function periodically.
See also
ResourceMetricCollector.daemonize().- Parameters:
on_collect (Callable[[Dict[str, float]], bool]) – A callback function that will be called periodically. It takes a dictionary containing the resource metrics and returns a boolean indicating whether to continue monitoring.
collector (Optional[ResourceMetricCollector]) – A
ResourceMetricCollectorinstance to collect metrics. If not given, it will collect metrics for all GPUs and subprocess of the current process.interval (Optional[float]) – The collect interval. If not given, use
collector.interval.on_start (Optional[Callable[[ResourceMetricCollector], None]]) – A function to initialize the daemon thread and collector.
on_stop (Optional[Callable[[ResourceMetricCollector], None]]) – A function that does some necessary cleanup after the daemon thread is stopped.
tag (str) – The tag prefix used for metrics results.
start (bool) – Whether to start the daemon thread on return.
- Returns: threading.Thread
A daemon thread object.
Examples
logger = ... def on_collect(metrics): # will be called periodically if logger.is_closed(): # closed manually by user return False logger.log(metrics) return True def on_stop(collector): # will be called only once at stop if not logger.is_closed(): logger.close() # cleanup # Record metrics to the logger in the background every 5 seconds. # It will collect 5-second mean/min/max for each metric. collect_in_background( on_collect, ResourceMetricCollector(Device.cuda.all()), interval=5.0, on_stop=on_stop, )
- class nvitop.ResourceMetricCollector(devices: Iterable[Device] | None = None, *, root_pids: Iterable[int] | None = None, interval: float = 1.0)[source]
Bases:
objectA class for collecting resource metrics.
- Parameters:
devices (Iterable[Device]) – Set of Device instances for logging. If not given, all physical devices on board will be used.
root_pids (Set[int]) – A set of PIDs, only the status of the descendant processes on the GPUs will be collected. If not given, the PID of the current process will be used.
interval (float) – The snapshot interval for background daemon thread.
Core methods:
collector.activate(tag='<tag>') # alias: start collector.deactivate() # alias: stop collector.clear(tag='<tag>') collector.collect() with collector(tag='<tag>'): ... collector.daemonize(on_collect_fn)
Examples
>>> import os >>> os.environ['CUDA_DEVICE_ORDER'] = 'PCI_BUS_ID' >>> os.environ['CUDA_VISIBLE_DEVICES'] = '3,2,1,0'
>>> from nvitop import ResourceMetricCollector, Device
>>> collector = ResourceMetricCollector() # log all devices and descendant processes of the current process on the GPUs >>> collector = ResourceMetricCollector(root_pids={1}) # log all devices and all GPU processes >>> collector = ResourceMetricCollector(devices=Device.cuda.all()) # use the CUDA ordinal
>>> with collector(tag='<tag>'): ... # Do something ... collector.collect() # -> Dict[str, float] # key -> '<tag>/<scope>/<metric (unit)>/<mean/min/max>' { '<tag>/host/cpu_percent (%)/mean': 8.967849777683456, '<tag>/host/cpu_percent (%)/min': 6.1, '<tag>/host/cpu_percent (%)/max': 28.1, ..., '<tag>/host/memory_percent (%)/mean': 21.5, '<tag>/host/swap_percent (%)/mean': 0.3, '<tag>/host/memory_used (GiB)/mean': 91.0136418208109, '<tag>/host/load_average (%) (1 min)/mean': 10.251427386878328, '<tag>/host/load_average (%) (5 min)/mean': 10.072539414569503, '<tag>/host/load_average (%) (15 min)/mean': 11.91126970422139, ..., '<tag>/cuda:0 (gpu:3)/memory_used (MiB)/mean': 3.875, '<tag>/cuda:0 (gpu:3)/memory_free (MiB)/mean': 11015.562499999998, '<tag>/cuda:0 (gpu:3)/memory_total (MiB)/mean': 11019.437500000002, '<tag>/cuda:0 (gpu:3)/memory_percent (%)/mean': 0.0, '<tag>/cuda:0 (gpu:3)/gpu_utilization (%)/mean': 0.0, '<tag>/cuda:0 (gpu:3)/memory_utilization (%)/mean': 0.0, '<tag>/cuda:0 (gpu:3)/fan_speed (%)/mean': 22.0, '<tag>/cuda:0 (gpu:3)/temperature (C)/mean': 25.0, '<tag>/cuda:0 (gpu:3)/power_usage (W)/mean': 19.11166264116916, '<tag>/cuda:0 (gpu:3)/power_limit (W)/mean': 250.0, ..., '<tag>/cuda:1 (gpu:2)/memory_used (MiB)/mean': 8878.875, ..., '<tag>/cuda:2 (gpu:1)/memory_used (MiB)/mean': 8182.875, ..., '<tag>/cuda:3 (gpu:0)/memory_used (MiB)/mean': 9286.875, ..., '<tag>/pid:12345/host/cpu_percent (%)/mean': 151.34342772112265, '<tag>/pid:12345/host/host_memory (MiB)/mean': 44749.72373447514, '<tag>/pid:12345/host/host_memory_percent (%)/mean': 8.675082352111717, '<tag>/pid:12345/host/running_time (min)': 336.23803206741576, '<tag>/pid:12345/cuda:1 (gpu:4)/gpu_memory (MiB)/mean': 8861.0, '<tag>/pid:12345/cuda:1 (gpu:4)/gpu_memory_percent (%)/mean': 80.4, '<tag>/pid:12345/cuda:1 (gpu:4)/gpu_memory_utilization (%)/mean': 6.711118172407917, '<tag>/pid:12345/cuda:1 (gpu:4)/gpu_sm_utilization (%)/mean': 48.23283397736476, ..., '<tag>/duration (s)': 7.247399162035435, '<tag>/timestamp': 1655909466.9981883 }
- DEVICE_METRICS: ClassVar[list[tuple[str, str, float | int]]] = [('memory_used', 'memory_used (MiB)', 1048576), ('memory_free', 'memory_free (MiB)', 1048576), ('memory_total', 'memory_total (MiB)', 1048576), ('memory_percent', 'memory_percent (%)', 1.0), ('gpu_utilization', 'gpu_utilization (%)', 1.0), ('memory_utilization', 'memory_utilization (%)', 1.0), ('fan_speed', 'fan_speed (%)', 1.0), ('temperature', 'temperature (C)', 1.0), ('power_usage', 'power_usage (W)', 1000.0), ('power_limit', 'power_limit (W)', 1000.0)]
- PROCESS_METRICS: ClassVar[list[tuple[str, str | None, str, float | int]]] = [('cpu_percent', 'host', 'cpu_percent (%)', 1.0), ('host_memory', 'host', 'host_memory (MiB)', 1048576), ('host_memory_percent', 'host', 'host_memory_percent (%)', 1.0), ('running_time_in_seconds', 'host', 'running_time (min)', 60.0), ('gpu_memory', None, 'gpu_memory (MiB)', 1048576), ('gpu_memory_percent', None, 'gpu_memory_percent (%)', 1.0), ('gpu_memory_utilization', None, 'gpu_memory_utilization (%)', 1.0), ('gpu_sm_utilization', None, 'gpu_sm_utilization (%)', 1.0)]
- __init__(devices: Iterable[Device] | None = None, *, root_pids: Iterable[int] | None = None, interval: float = 1.0) None[source]
Initialize the resource metric collector.
- interval: float
- activate(tag: str) ResourceMetricCollector[source]
Start a new metric collection with the given tag.
- Parameters:
tag (str) – The name of the new metric collection. The tag will be used to identify the metric collection. It must be a unique string.
Examples
>>> collector = ResourceMetricCollector()
>>> collector.activate(tag='train') # key prefix -> 'train' >>> collector.activate(tag='batch') # key prefix -> 'train/batch' >>> collector.deactivate() # key prefix -> 'train' >>> collector.deactivate() # the collector has been stopped >>> collector.activate(tag='test') # key prefix -> 'test'
- start(tag: str) ResourceMetricCollector
Start a new metric collection with the given tag.
- Parameters:
tag (str) – The name of the new metric collection. The tag will be used to identify the metric collection. It must be a unique string.
Examples
>>> collector = ResourceMetricCollector()
>>> collector.activate(tag='train') # key prefix -> 'train' >>> collector.activate(tag='batch') # key prefix -> 'train/batch' >>> collector.deactivate() # key prefix -> 'train' >>> collector.deactivate() # the collector has been stopped >>> collector.activate(tag='test') # key prefix -> 'test'
- deactivate(tag: str | None = None) ResourceMetricCollector[source]
Stop the current collection with the given tag and remove all sub-tags.
If the tag is not specified, deactivate the current active collection. For nested collections, the sub-collections will be deactivated as well.
- stop(tag: str | None = None) ResourceMetricCollector
Stop the current collection with the given tag and remove all sub-tags.
If the tag is not specified, deactivate the current active collection. For nested collections, the sub-collections will be deactivated as well.
- context(tag: str) Generator[ResourceMetricCollector][source]
A context manager for starting and stopping resource metric collection.
- Parameters:
tag (str) – The name of the new metric collection. The tag will be used to identify the metric collection. It must be a unique string.
Examples
>>> collector = ResourceMetricCollector()
>>> with collector.context(tag='train'): # key prefix -> 'train' ... # Do something ... collector.collect() # -> Dict[str, float]
- __call__(tag: str) Generator[ResourceMetricCollector]
A context manager for starting and stopping resource metric collection.
- Parameters:
tag (str) – The name of the new metric collection. The tag will be used to identify the metric collection. It must be a unique string.
Examples
>>> collector = ResourceMetricCollector()
>>> with collector.context(tag='train'): # key prefix -> 'train' ... # Do something ... collector.collect() # -> Dict[str, float]
- clear(tag: str | None = None) None[source]
Clear the metric collection with the given tag.
If the tag is not specified, clear the current active collection. For nested collections, the sub-collections will be cleared as well.
- Parameters:
tag (Optional[str]) – The tag to clear. If
None, the current active collection will be reset.
Examples
>>> collector = ResourceMetricCollector()
>>> with collector(tag='train'): # key prefix -> 'train' ... time.sleep(5.0) ... collector.collect() # metrics within the 5.0s interval ... ... time.sleep(5.0) ... collector.collect() # metrics within the cumulative 10.0s interval ... ... collector.clear() # clear the active collection ... time.sleep(5.0) ... collector.collect() # metrics within the 5.0s interval ... ... with collector(tag='batch'): # key prefix -> 'train/batch' ... collector.clear(tag='train') # clear both 'train' and 'train/batch'
- reset(tag: str | None = None) None
Clear the metric collection with the given tag.
If the tag is not specified, clear the current active collection. For nested collections, the sub-collections will be cleared as well.
- Parameters:
tag (Optional[str]) – The tag to clear. If
None, the current active collection will be reset.
Examples
>>> collector = ResourceMetricCollector()
>>> with collector(tag='train'): # key prefix -> 'train' ... time.sleep(5.0) ... collector.collect() # metrics within the 5.0s interval ... ... time.sleep(5.0) ... collector.collect() # metrics within the cumulative 10.0s interval ... ... collector.clear() # clear the active collection ... time.sleep(5.0) ... collector.collect() # metrics within the 5.0s interval ... ... with collector(tag='batch'): # key prefix -> 'train/batch' ... collector.clear(tag='train') # clear both 'train' and 'train/batch'
- daemonize(on_collect: Callable[[dict[str, float]], bool], interval: float | None = None, *, on_start: Callable[[ResourceMetricCollector], None] | None = None, on_stop: Callable[[ResourceMetricCollector], None] | None = None, tag: str = 'metrics-daemon', start: bool = True) threading.Thread[source]
Start a background daemon thread that collect and call the callback function periodically.
See also
collect_in_background().- Parameters:
on_collect (Callable[[Dict[str, float]], bool]) – A callback function that will be called periodically. It takes a dictionary containing the resource metrics and returns a boolean indicating whether to continue monitoring.
interval (Optional[float]) – The collect interval. If not given, use
collector.interval.on_start (Optional[Callable[[ResourceMetricCollector], None]]) – A function to initialize the daemon thread and collector.
on_stop (Optional[Callable[[ResourceMetricCollector], None]]) – A function that do some necessary cleanup after the daemon thread is stopped.
tag (str) – The tag prefix used for metrics results.
start (bool) – Whether to start the daemon thread on return.
- Returns: threading.Thread
A daemon thread object.
Examples
logger = ... def on_collect(metrics): # will be called periodically if logger.is_closed(): # closed manually by user return False logger.log(metrics) return True def on_stop(collector): # will be called only once at stop if not logger.is_closed(): logger.close() # cleanup # Record metrics to the logger in the background every 5 seconds. # It will collect 5-second mean/min/max for each metric. ResourceMetricCollector(Device.cuda.all()).daemonize( on_collect, ResourceMetricCollector(Device.cuda.all()), interval=5.0, on_stop=on_stop, )
- take_snapshots() SnapshotResult[source]
Take snapshots of the current resource metrics and update the metric buffer.
- nvitop.ttl_cache(maxsize: int | None = 128, *, ttl: float = 600.0, timer: Callable[[], float] = time.monotonic, typed: bool = False) Callable[[Callable[_P, _T]], Callable[_P, _T]][source]
- nvitop.ttl_cache(maxsize: Callable[_P, _T], *, ttl: float = 600.0, timer: Callable[[], float] = time.monotonic, typed: bool = False) Callable[_P, _T]
Time aware cache decorator.
- nvitop.bytes2human(b: int | float | NaType, /, *, min_unit: int = 1) str[source]
Convert bytes to a human-readable string.
- nvitop.human2bytes(s: int | str, /) int[source]
Convert a human-readable size string (case insensitive) to bytes.
- Raises:
ValueError – If cannot convert the given size string.
Examples
>>> human2bytes('200') 200 >>> human2bytes('500B') 500 >>> human2bytes('10k') 10000 >>> human2bytes('10ki') 10240 >>> human2bytes('1M') 1000000 >>> human2bytes('1MiB') 1048576 >>> human2bytes('1.5GiB') 1610612736
- nvitop.timedelta2human(dt: int | float | timedelta | NaType, /, *, round: bool = False) str[source]
Convert a number in seconds or a
datetime.timedeltainstance to a human-readable string.
- nvitop.utilization2string(utilization: int | float | NaType, /) str[source]
Convert a utilization rate to string.
- nvitop.colored(text: Any, /, color: termcolor.Color | None = None, on_color: termcolor.Highlight | None = None, attrs: Iterable[termcolor.Attribute] | None = None) str[source]
Colorize text with ANSI color escape codes.
- Available text colors:
red, green, yellow, blue, magenta, cyan, white.
- Available text highlights:
on_red, on_green, on_yellow, on_blue, on_magenta, on_cyan, on_white.
- Available attributes:
bold, dark, underline, blink, reverse, concealed.
Examples
>>> colored('Hello, World!', 'red', 'on_grey', ['bold', 'blink']) '...Hello, World!...' >>> colored('Hello, World!', 'green') '...Hello, World!...'
- nvitop.boolify(string: str, /, default: Any = None) bool[source]
Convert the given value, usually a string, to boolean.
- class nvitop.Snapshot(real: Any, **items: Any)[source]
Bases:
objectA dict-like object holds the snapshot values.
The value can be accessed by
snapshot.nameorsnapshot['name']syntax. The Snapshot can also be converted to a dictionary bydict(snapshot)or{**snapshot}.Missing attributes will be automatically fetched from the original object.
- __init__(real: Any, **items: Any) None[source]
Initialize a new
Snapshotobject with the given attributes.
- __getattr__(name: str) Any[source]
Get a member from the instance.
If the attribute is not defined, fetches from the original object and makes a function call.
- __setattr__(name: str, value: Any) None[source]
Set or update a member of the instance.
If the attribute is not defined, set it to the snapshot object.
- nvitop.select_devices(devices: Iterable[Device] | None = None, *, format: Literal['index'] = 'index', force_index: bool = False, min_count: int = 0, max_count: int | None = None, min_free_memory: int | str | None = None, min_total_memory: int | str | None = None, max_gpu_utilization: int | None = None, max_memory_utilization: int | None = None, tolerance: int = 0, free_accounts: list[str] | None = None, sort: bool = True) list[int] | list[tuple[int, int]][source]
- nvitop.select_devices(devices: Iterable[Device] | None = None, *, format: Literal['uuid'], force_index: bool = False, min_count: int = 0, max_count: int | None = None, min_free_memory: int | str | None = None, min_total_memory: int | str | None = None, max_gpu_utilization: int | None = None, max_memory_utilization: int | None = None, tolerance: int = 0, free_accounts: list[str] | None = None, sort: bool = True) list[str]
- nvitop.select_devices(devices: Iterable[Device] | None = None, *, format: Literal['device'], force_index: bool = False, min_count: int = 0, max_count: int | None = None, min_free_memory: int | str | None = None, min_total_memory: int | str | None = None, max_gpu_utilization: int | None = None, max_memory_utilization: int | None = None, tolerance: int = 0, free_accounts: list[str] | None = None, sort: bool = True) list[Device]
Select a subset of devices satisfying the specified criteria.
Note
The min count constraint may not be satisfied if not enough devices are available. This constraint is only enforced when there are both MIG and non-MIG devices present.
Examples
Put the following lines to the top of your script:
import os from nvitop import select_devices os.environ['CUDA_VISIBLE_DEVICES'] = ','.join( select_devices(format='uuid', min_count=4, min_free_memory='8GiB') )
- Parameters:
devices (Iterable[Device]) – The device superset to select from. If not specified, use all devices as the superset.
format (str) – The format of the output. One of
'index','uuid', or'device'. If gets any MIG device with format'index'set, falls back to the'uuid'format.force_index (bool) – If
True, always use the device index as the output format when gets any MIG device.min_count (int) – The minimum number of devices to select.
max_count (Optional[int]) – The maximum number of devices to select.
min_free_memory (Optional[Union[int, str]]) – The minimum free memory (an
intin bytes or astrin human-readable form) of the selected devices.min_total_memory (Optional[Union[int, str]]) – The minimum total memory (an
intin bytes or astrin human-readable form) of the selected devices.max_gpu_utilization (Optional[int]) – The maximum GPU utilization rate (in percentage) of the selected devices.
max_memory_utilization (Optional[int]) – The maximum memory bandwidth utilization rate (in percentage) of the selected devices.
tolerance (int) – The tolerance rate (in percentage) to loose the constraints.
free_accounts (List[str]) – A list of accounts whose used GPU memory needs be considered as free memory.
sort (bool) – If
True, sort the selected devices by memory usage and GPU utilization.
- Returns:
A list of the device identifiers.